Yang Liu Assistant Professor, PhD Supervisor


Peking University
No. 128 Zhongguancun North Street,
Haidian District, Beijing,100871, China
E-mail: yangliu "at" pku.edu.cn
I am now a Tenure-track Assistant Professor (Ph.D. Supervisor) in Wangxuan Institute of Computer Technology, Peking University, Peking University Boya Young Fellow. Also a member of MIPL Group (led by Prof. Yuxin Peng) at Peking University.
Before joining Peking University, I was a Postdoctoral Researcher in the Visual Geometry Group (VGG) at University of Oxford, supervised by Prof. Andrew Zisserman. I received PhD and MPhil in Advanced Computer Science from University of Cambridge, and B.Eng. in Telecommunication Engineering from Beijing University of Posts and Telecommunications (BUPT).
My research interests include computer vision, natural language processing and machine learning, with an emphasis on how these areas can collaborate best to perform real-world tasks. Below are some of my recent research topic:
We are always actively recruiting postdocs, Prospective graduate students and interns!
Welcome to contact me with your detailed CV! Please read this Note first!
Selected Publications

|
Temporal-Aware Reasoning Optimization for Video Temporal Grounding Minghang Zheng, Zihao Yin, Yi Yang, Yuxin Peng, Yang Liu† Forty-third International Conference on Machine Learning (ICML), 2026 [ PDF] [Project Page] [ Code] [ Video] [公众号] [ Bibtex] |

|
Taming I2V models for Image HOI Editing: A Cognitive Benchmark and Agentic Self-Correcting Framework Jiayi Gao, Qingchao Chen, Yuxin Peng, Yang Liu† Forty-third International Conference on Machine Learning (ICML), 2026 [ PDF] [Project Page] [ Code] [ Video] [公众号] [ Bibtex] |
|
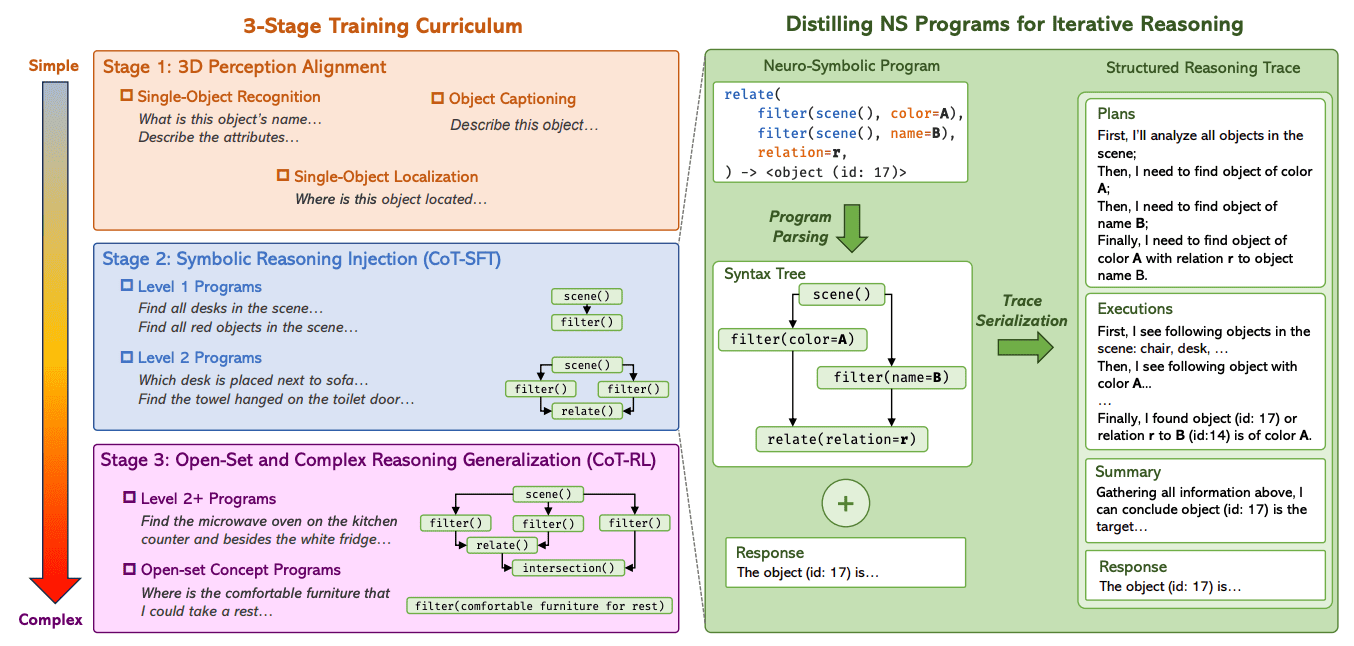
Distilling Neuro-Symbolic Programs into 3D Multi-modal LLMs Wentao Mo, Yang Liu† Forty-third International Conference on Machine Learning (ICML), 2026 [ PDF] [Project Page] [ Code] [ Video] [公众号] [ Bibtex] |

|
Scalable Object Relation Encoding for Better 3D Spatial Reasoning in Large Language Models Shengli Zhou, Minghang Zheng, Feng Zheng, Yang Liu† IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026 [ PDF] [Project Page] [ Code] [ Video] [公众号] [ Bibtex] |
|
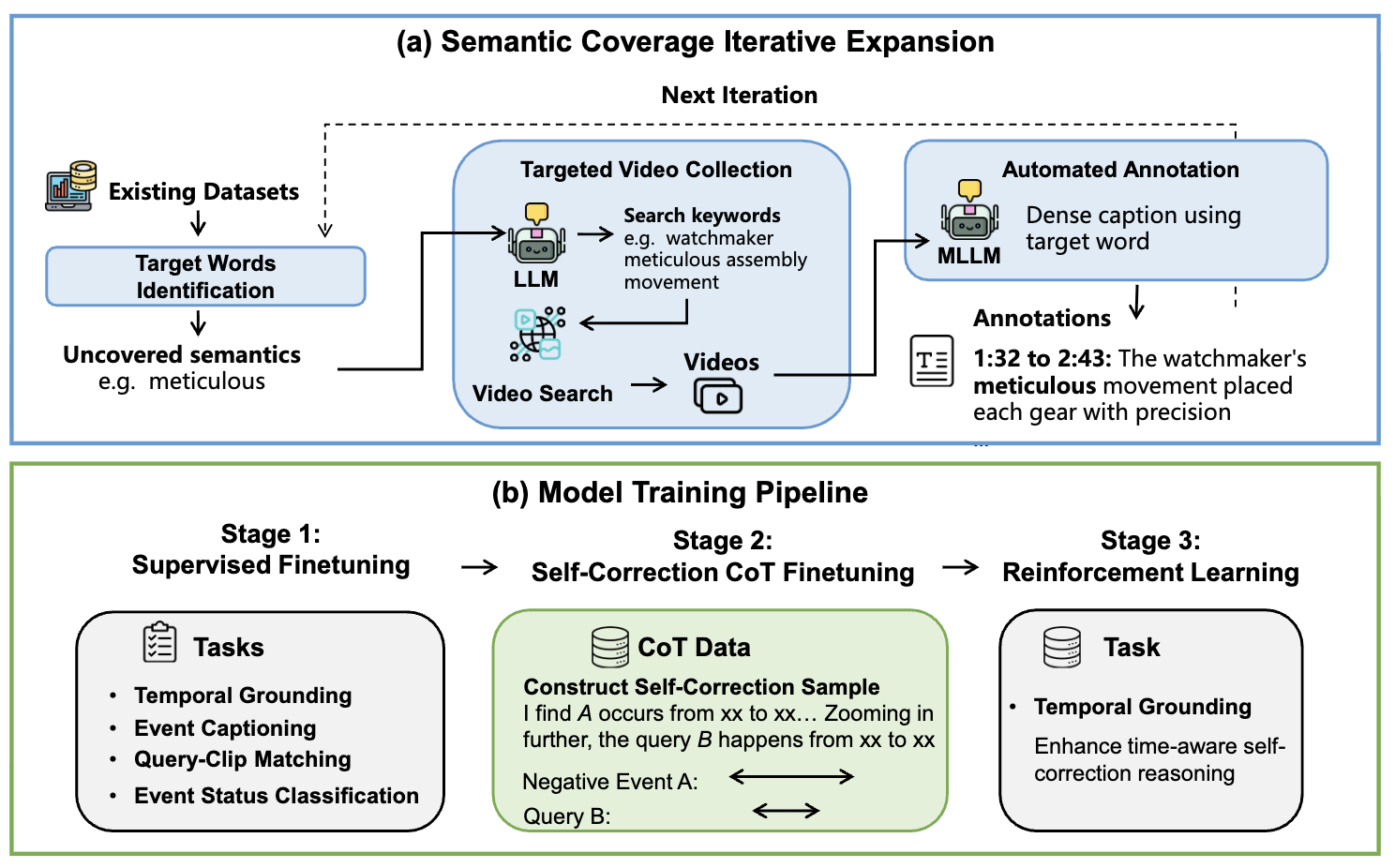
OmniVTG: A Large-Scale Dataset and Training Paradigm for open-World Video Temporal Grounding Minghang Zheng, Zihao Yin, Yi Yang, Yuxin Peng, Yang Liu† IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026 [ PDF] [Project Page] [ Code] [ Model] [ Video] [公众号] [ Bibtex] |
|
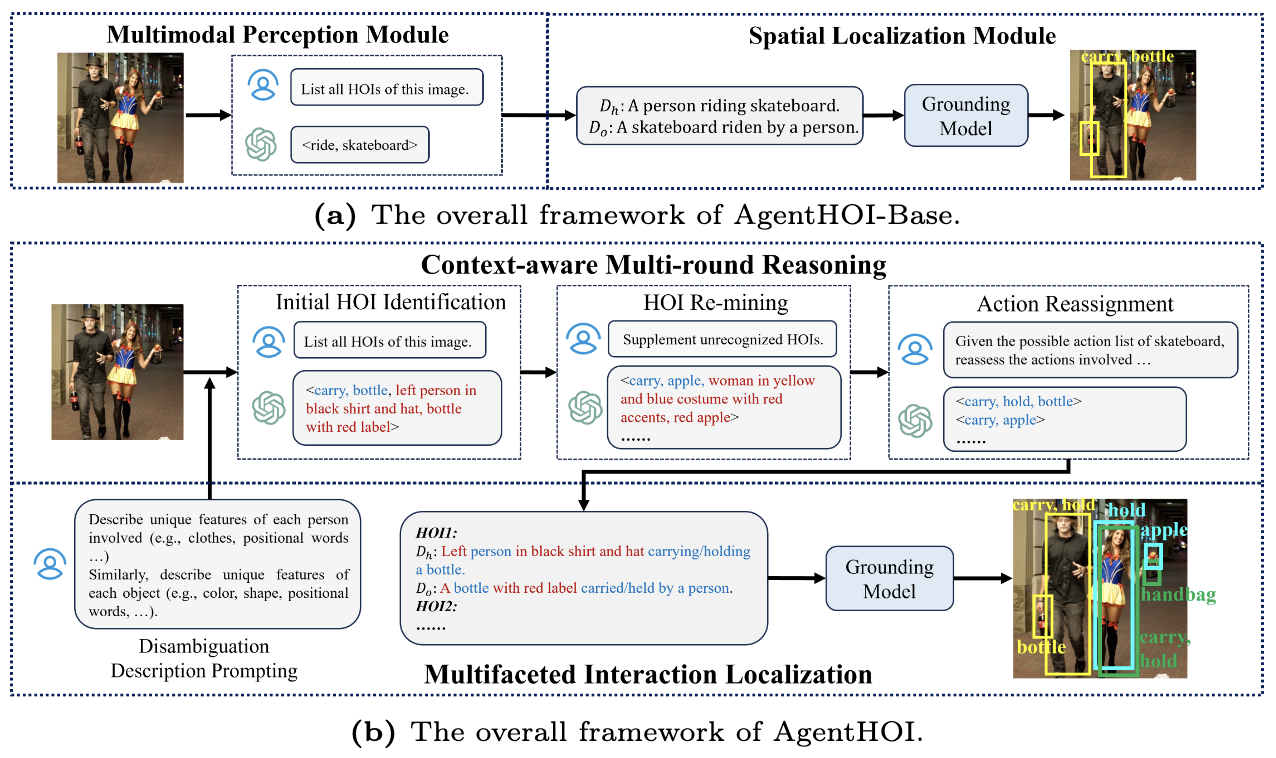
Unleashing Multimodal Large Language Models for Training-free HOI Detection in the Wild Ting Lei, Jialin Liu, Zhu Xu, Yuxin Peng, Yang Liu† European Conference on Computer Vision (ECCV), 2026 [ PDF] [Project Page] [ Code] [ Bibtex] |
|
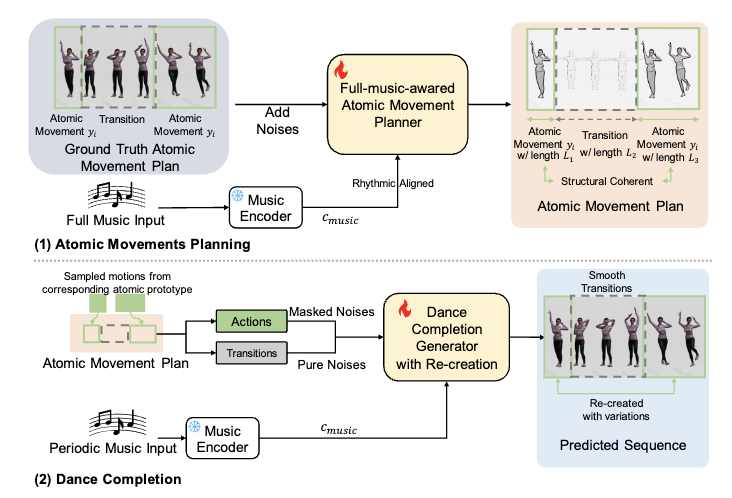
Music-to-Dance Generation via Atomic Movements Xinhao Cai, Yixuan Sun, Minghang Zheng, Qingchao Chen, Xin Jin, Yang Liu† European Conference on Computer Vision (ECCV), 2026 [ PDF] [Project Page] [ Code] [ Bibtex] |
|
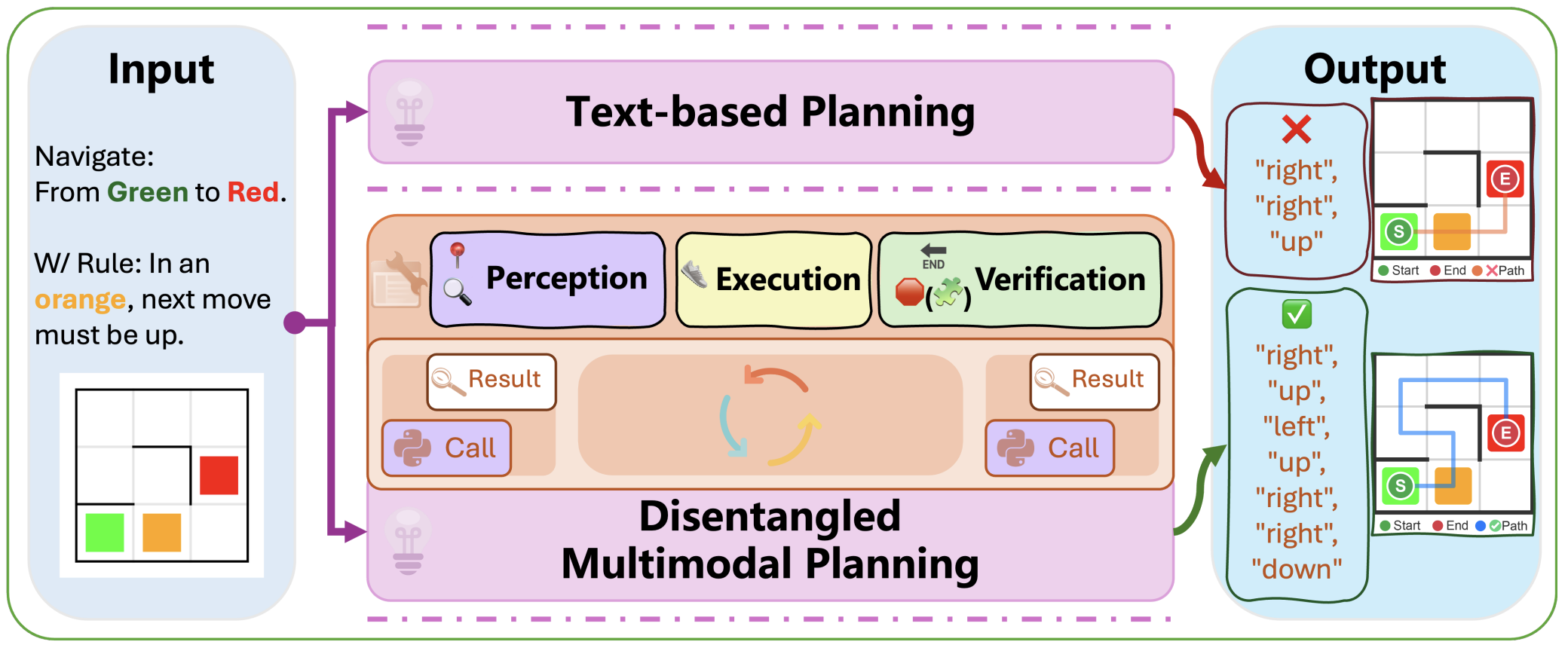
Rule-Compliant Visual Spatial Planning for Multimodal Large Language Models Yu Chen, Ting Lei, Yaoyi Li, Jia Cai, Zhecen Wu, Yang Liu† ACM International Conference on Multimedia (ACM-MM), 2026 [Coming soon] |
|
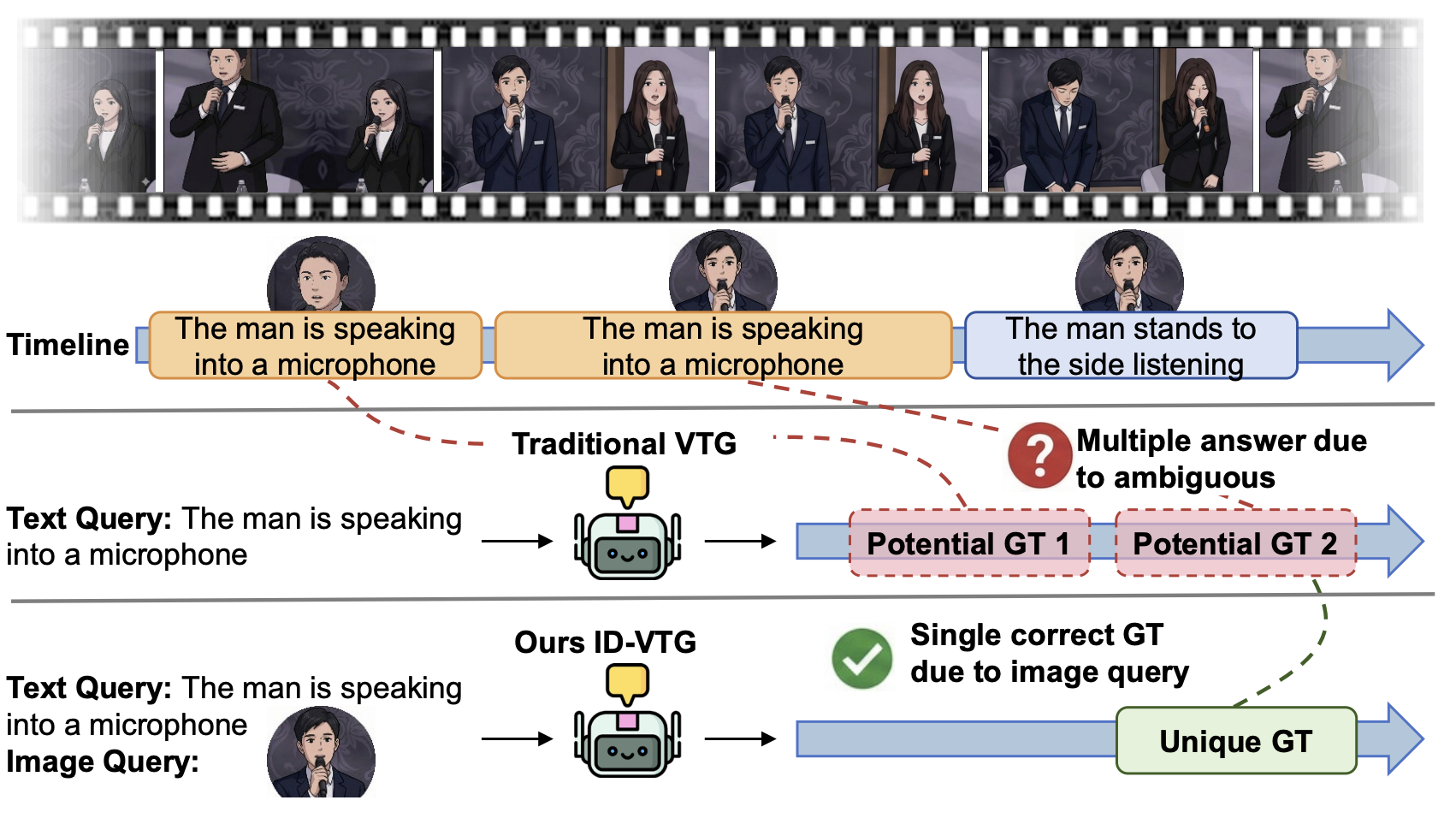
ID-VTG: Image-Disambiguated Video Temporal Grounding Minghang Zheng, Jingli Wei, Hong-Yi Yang, Yang Liu† ACM International Conference on Multimedia (ACM-MM), 2026 [Coming soon] |
|
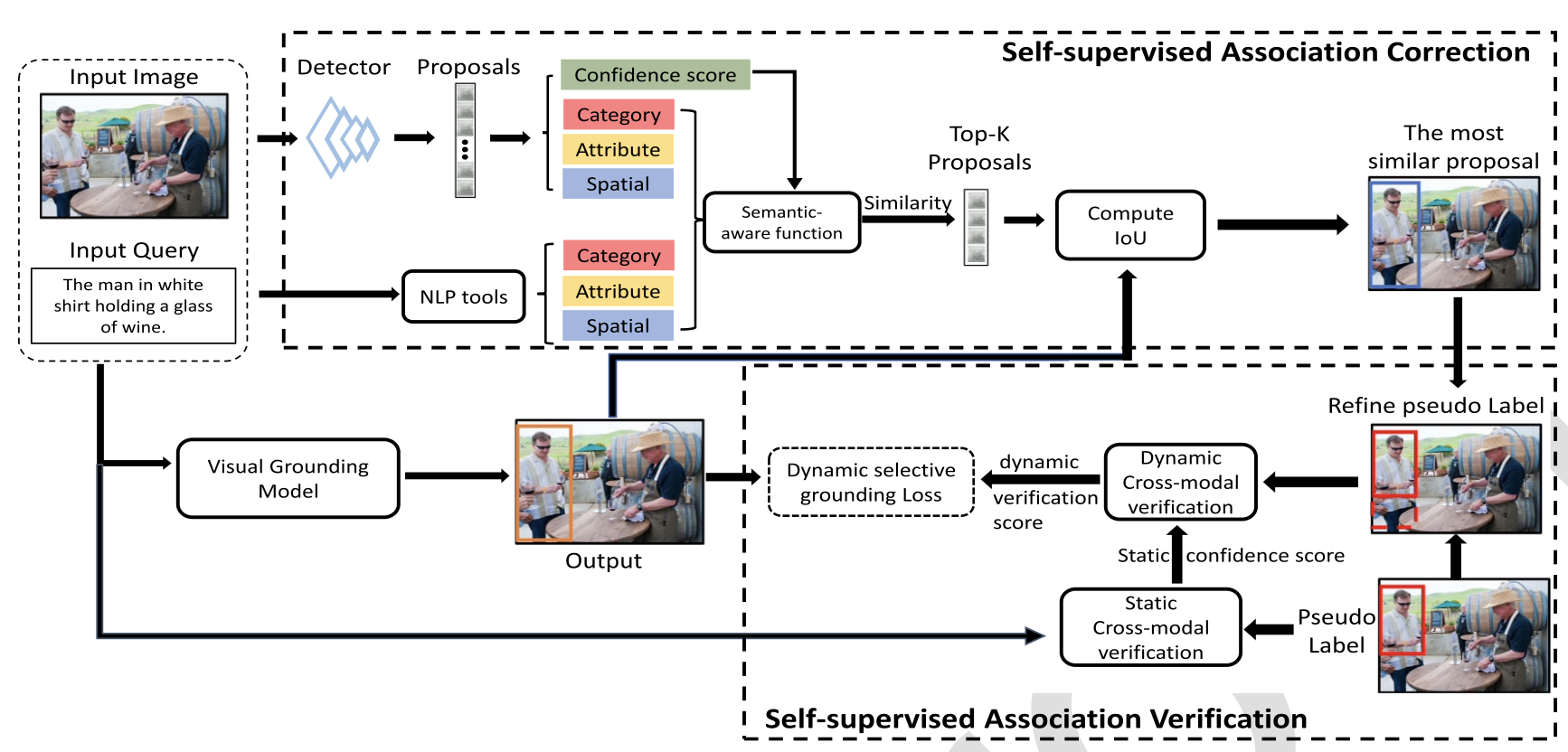
Confidence-Aware Pseudo-Label Self-Correction for Weakly Supervised Visual Grounding Yang Liu, Jiahua Zhang, Yue Wu, Zijing Zhao, Qingchao Chen, Yuxin Peng IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2026 [ PDF] [ Code] [公众号] [ Bibtex] |

|
Identity-Preserving Text-to-Video Generation via Training-Free Prompt, Image, and Guidance Enhancement Winner of ACM-MM 2025 Identity-Preserving Video Generation Challenge Jiayi Gao, Changcheng Hua, Qingchao Chen, Yuxin Peng, Yang Liu† ACM International Conference on Multimedia (ACM-MM), 2025 [ PDF] [Project Page] [ Code] [ Challenge] [ Bibtex] |
|
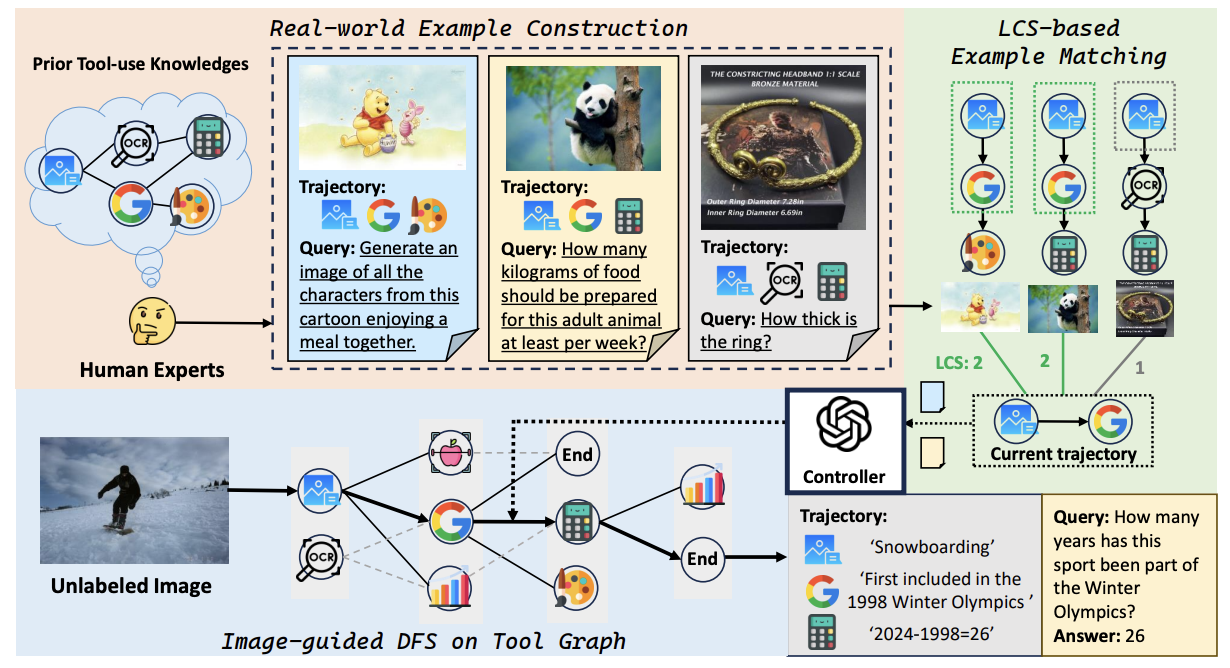
ToolVQA: A Dataset for Multi-step Reasoning VQA with External Tools Winner of CVPR-2025 Cultural VQA challenge Shaofeng Yin, Ting Lei, Yang Liu† International Conference on Computer Vision (ICCV), 2025 [ PDF] [Project Page] [ Code] [ Challenge] [公众号] [ Bibtex] |

|
Weakly and Single-Frame Supervised Temporal Sentence Grounding With Gaussian-Based Contrastive Proposal Learning Minghang Zheng, Yanjie Huang,Qingchao Chen, Yuxin Peng, Yang Liu† IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025 [ PDF] [ Bibtex] |
|
Large-Scale Pre-trained Models Empowering Phrase Generalization in Temporal Sentence Localization Yang Liu, Minghang Zheng, Qingchao Chen, Shaogang Gong, Yuxin Peng International Journal of Computer Vision (IJCV), 2025 [ PDF] [ Bibtex] |
|
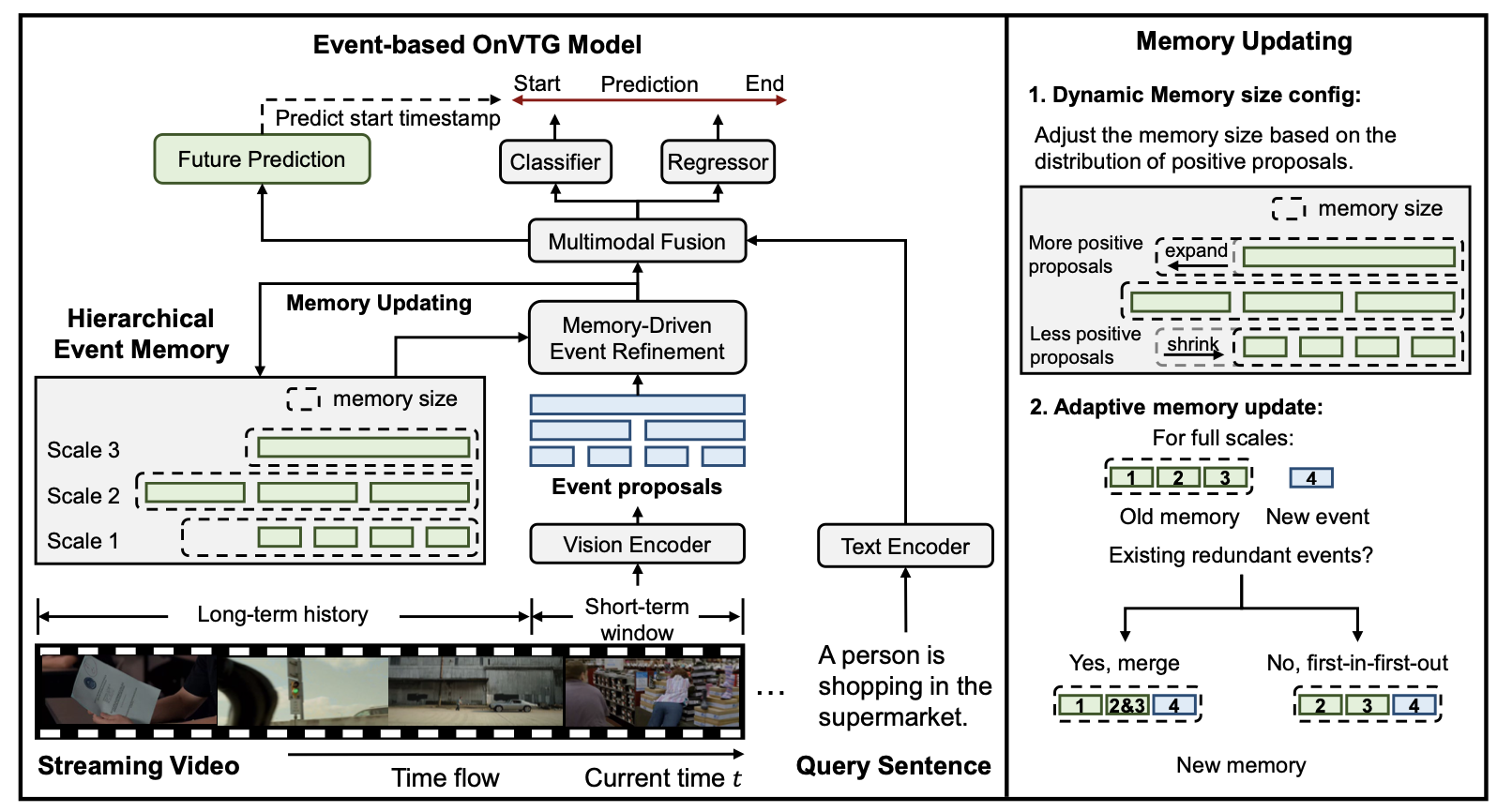
Hierarchical Event Memory for Accurate and Low-latency Online Video Temporal Grounding Minghang Zheng, Yuxin Peng, Benyuan Sun, Yi Yang, Yang Liu† International Conference on Computer Vision (ICCV), 2025 [ PDF] [Project Page] [ Code] [ Bibtex] |
|
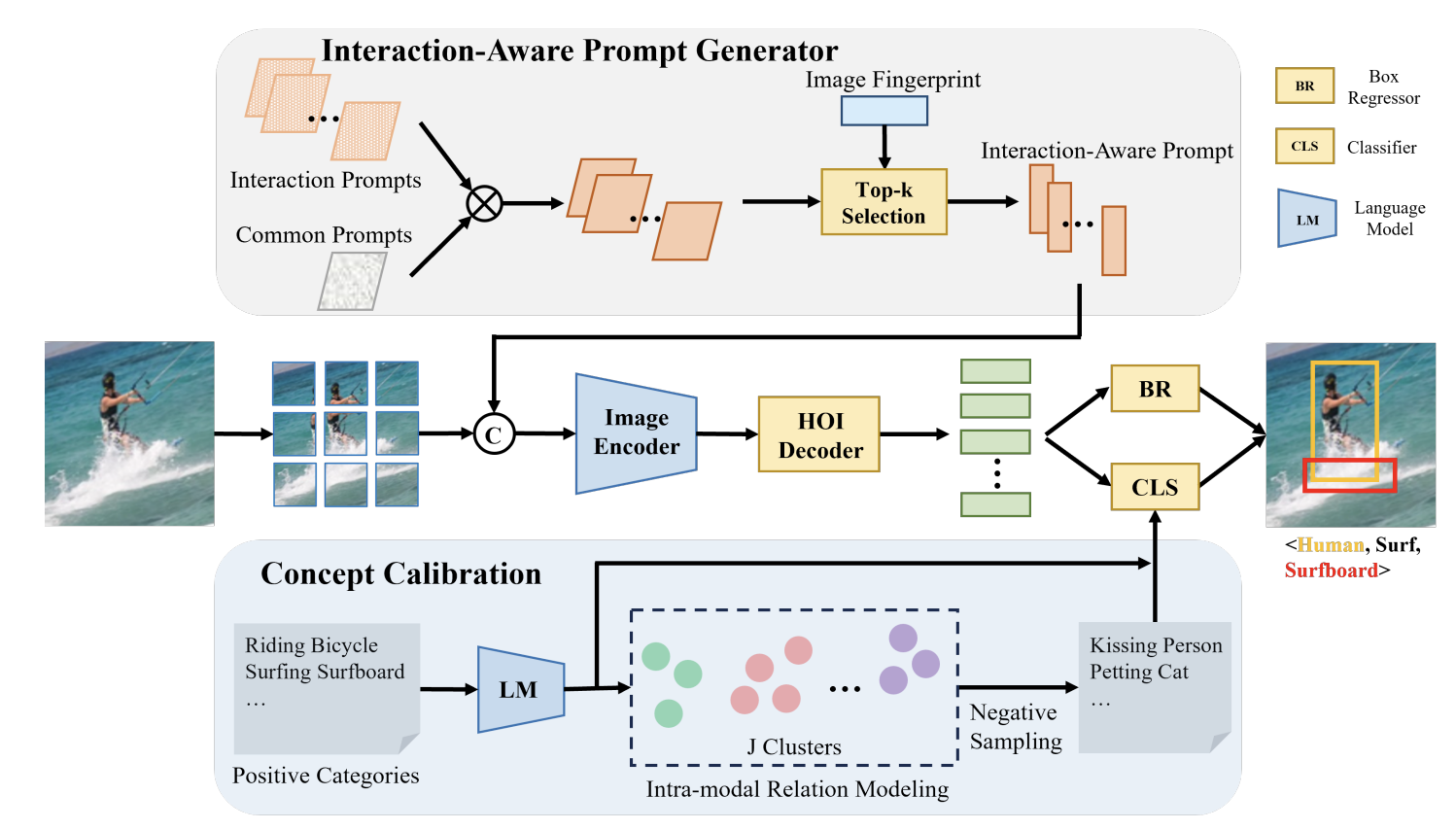
Open-Vocabulary HOI Detection with Interaction-aware Prompt and Concept Calibration Ting Lei, Shaofeng Yin, Qingchao Chen, Yuxin Peng, Yang Liu† International Conference on Computer Vision (ICCV), 2025 [ PDF] [Project Page] [ Code] [公众号] [ Bibtex] |
|
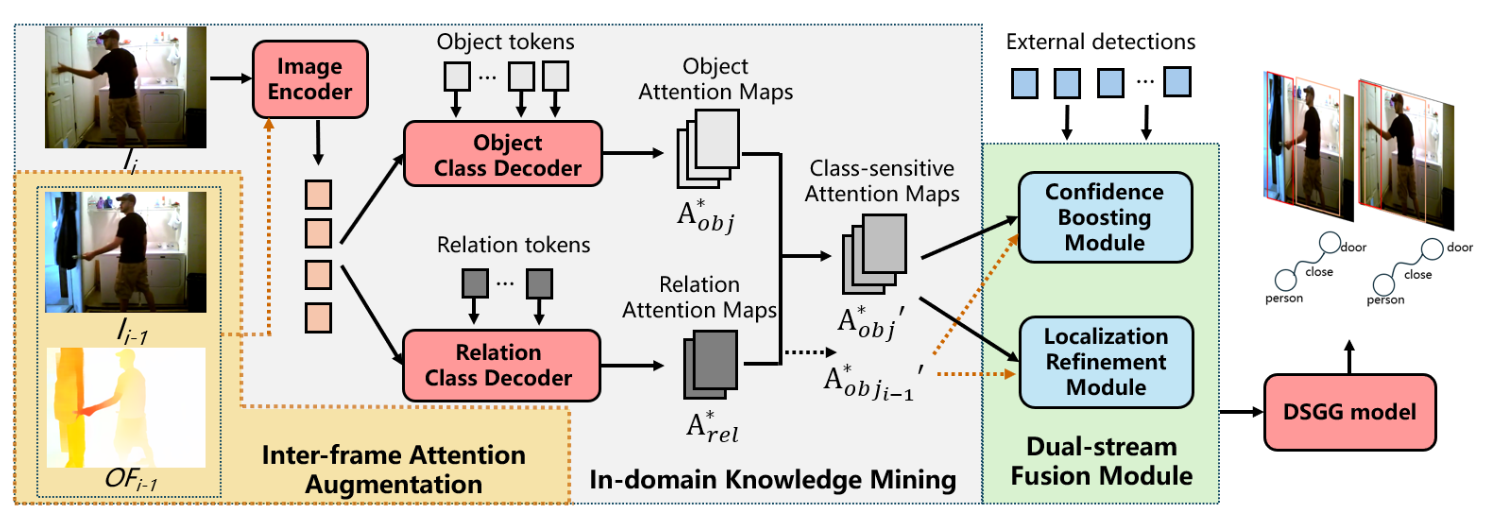
Weakly Supervised Dynamic Scene Graph Generation with Temporal-enhanced In-domain Knowledge Transferring Zhu Xu, Ting Lei, Zhimin Li, Guan Wang, Qingchao Chen, Yuxin Peng, Yang Liu† International Conference on Computer Vision (ICCV), 2025 [ PDF] [Project Page] [ Code] [ Bibtex] |
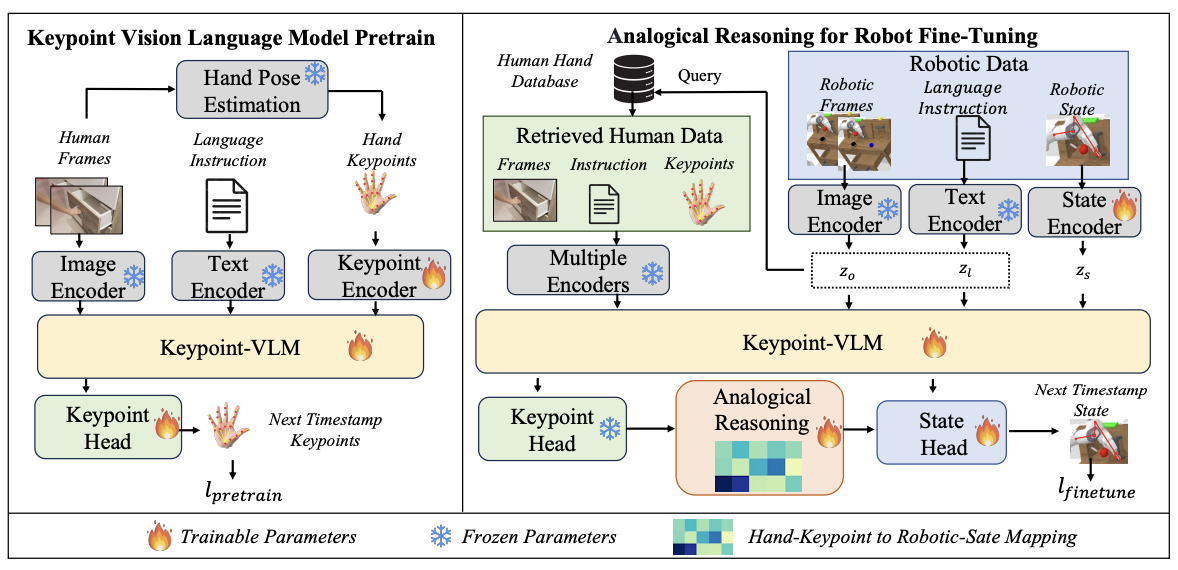
|
AR-VRM: Imitating Human Motions for Visual Robot Manipulation with Analogical Reasoning Dejie Yang, Zijing Zhao, Yang Liu† International Conference on Computer Vision (ICCV), 2025 [ PDF] [Project Page] [ Code] [公众号] [ Bibtex] |

|
VideoLLaMB: Long Streaming Video Understanding with Recurrent Memory Bridges Yuxuan Wang, Yiqi Song, Cihang Xie, Yang Liu, Zilong Zheng International Conference on Computer Vision (ICCV), 2025 [ PDF] [Project Page] [ Code] [公众号] [ Bibtex] |
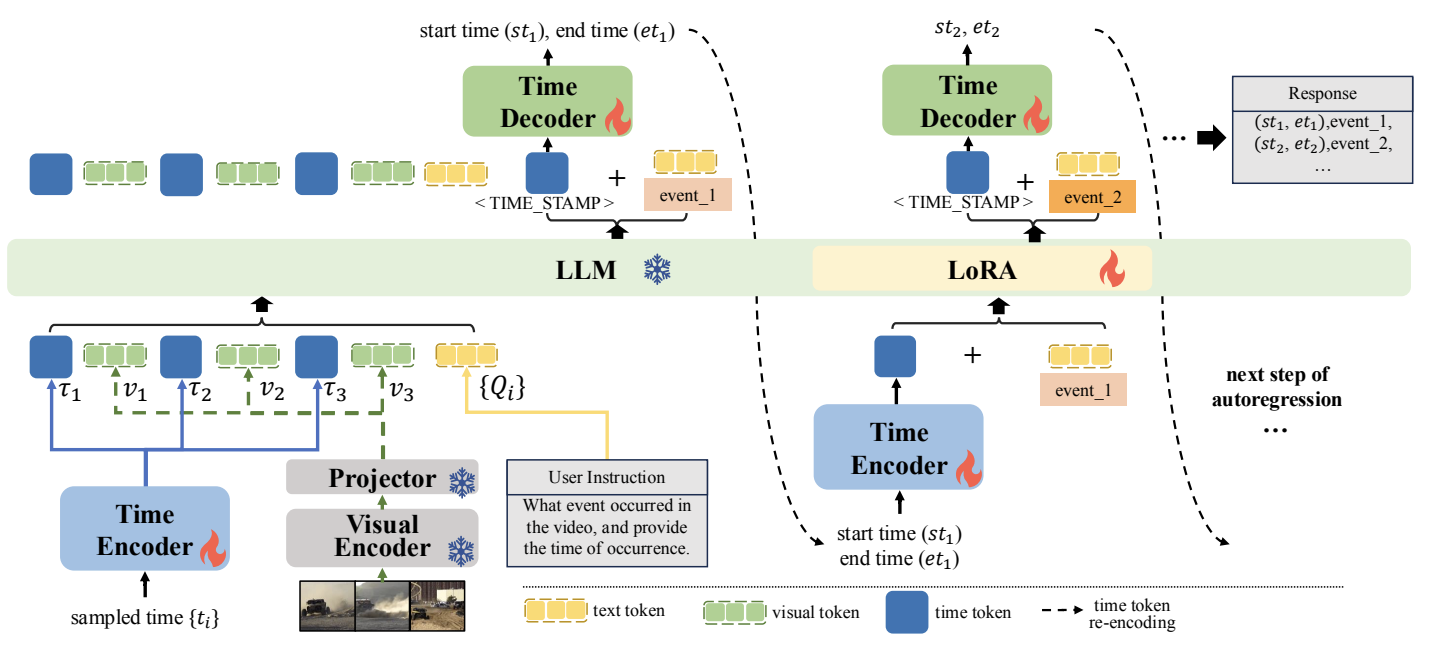
|
DisTime: Distribution-based Time Representation for Video Large Language Models Yingsen Zeng, Zepeng Huang, Yujie Zhong, Chengjian Feng, Jie Hu, Lin Ma, Yang Liu International Conference on Computer Vision (ICCV), 2025 [ PDF] [Dataseat] [ Code] [ Bibtex] |
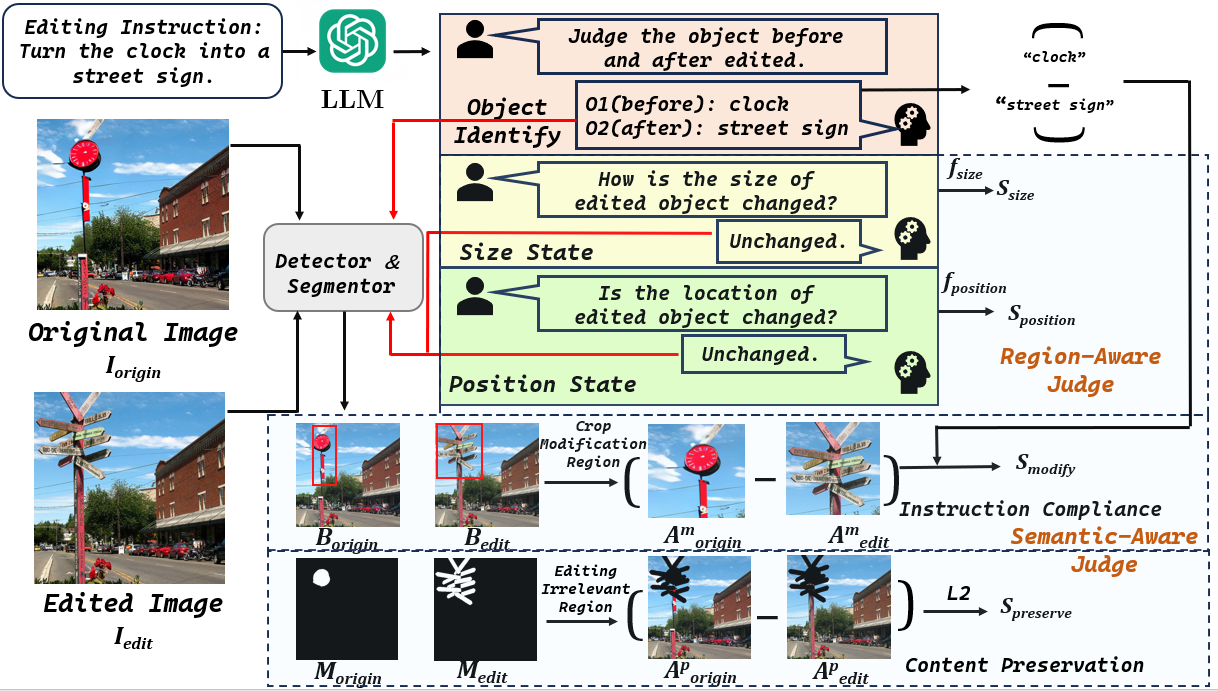
|
Balancing Preservation and Modification: A Region and Semantic Aware Metric for Instruction-Based Image Editing Zhuoying Li, Zhu Xu, Yuxin Peng, Yang Liu† International Conference on Machine Learning (ICML), 2025 [ PDF] [Project Page] [ Code] [Video] [ Bibtex] |

|
ConMo: Controllable Motion Disentanglement and Recomposition for Zero-Shot Motion Transfer Jiayi Gao, Zijin Yin, Changcheng Hua, Yuxin Peng, Kongming Liang,Zhanyu Ma,Jun Guo, Yang Liu† IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025 [ PDF] [Project Page] [ Code] [Video] [ Bibtex] |

|
Apply Hierarchical-Chain-of-Generation to Complex Attributes Text-to-3D Generation Yiming Qin, Zhu Xu, Yang Liu† IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025 [ PDF] [Project Page] [ Code] [Video] [公众号] [ Bibtex] |
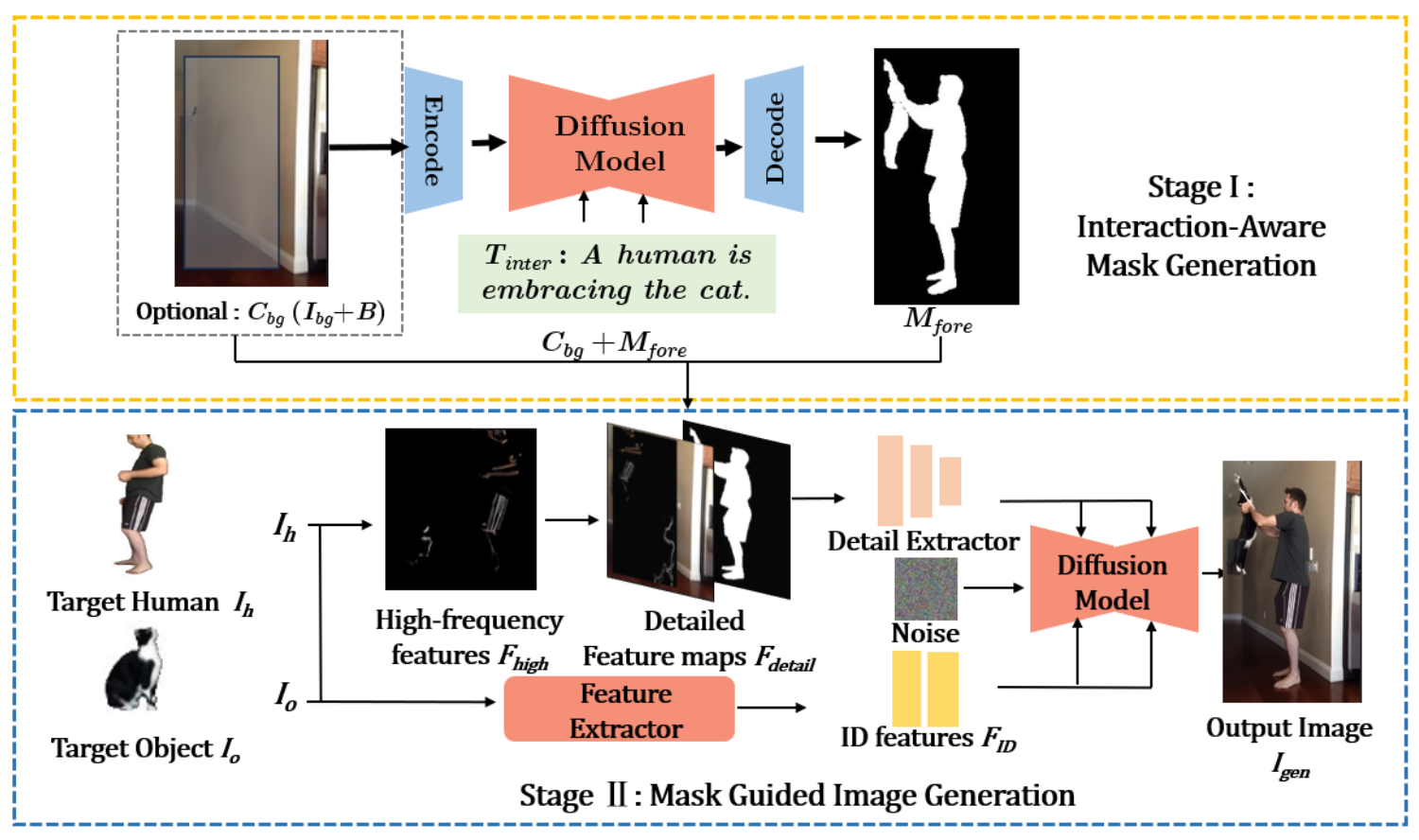
|
Customized Human Object Interaction Image Generation Zhu Xu, Zhaowen Wang, Yuxin Peng, Yang Liu† ACM International Conference on Multimedia (ACM-MM), 2025 [ PDF] [Project Page] [ Code] [ Bibtex] |

|
InteractMove: Text-Controlled Human-Object Interaction Generation in 3D Scenes with Movable Objects Xinhao Cai, Minghang Zheng, Xin Jin, Yang Liu† ACM International Conference on Multimedia (ACM-MM), 2025 [ PDF] [Project Page] [ Code] [ Bibtex] |

|
Advancing 3D Scene Understanding with MV-ScanQA Multi-View Reasoning Evaluation and TripAlign Pre-training Dataset Wentao Mo, Qingchao Chen, Yuxin Peng, Siyuan Huang, Yang Liu† ACM International Conference on Multimedia (ACM-MM) Dataset Track, 2025 [PDF] [Project Page] [ Code] [ Bibtex] |
|
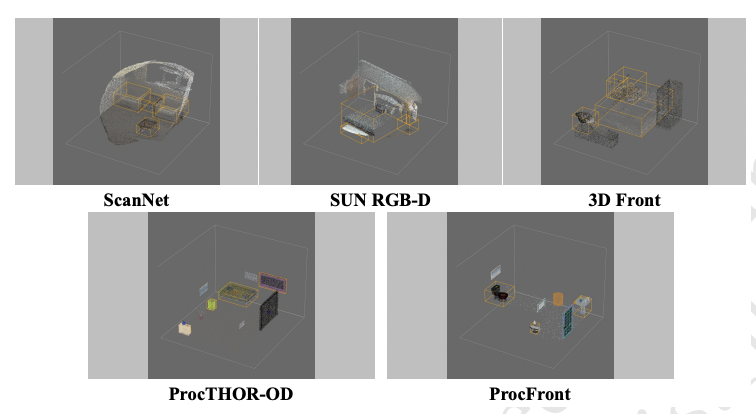
Investigating Domain Gaps for Indoor 3D Object Detection Zijing Zhao, Zhu Xu, Qingchao Chen, Yuxin Peng, Yang Liu† ACM International Conference on Multimedia (ACM-MM) Dataset Track, 2025 [PDF] [Project Page] [ Code] [ Bibtex] |
|
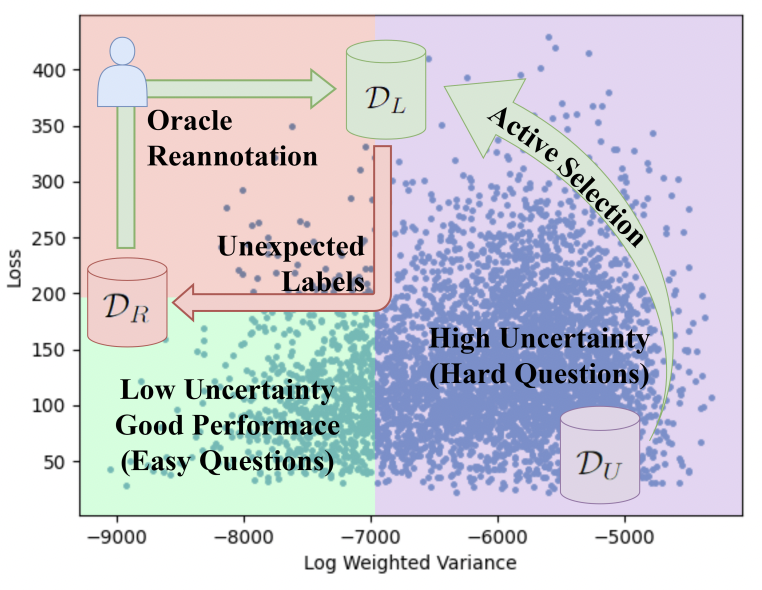
Learn 3D VQA Better with Active Selection and Reannotation Shengli Zhou, Yang Liu,Feng Zheng ACM International Conference on Multimedia (ACM-MM), 2025 [ PDF] [ Code] [ Bibtex] |

|
PlanLLM: Video Procedure Planning with Refinable Large Language Models Dejie Yang, Zijing Zhao, Yang Liu† Conference on Artificial Intelligence (AAAI), 2025 [ PDF] [Project Page] [ Code] [公众号] [ Bibtex] |

|
Generative Video Diffusion for Unseen Cross-Domain Video Moment Retrieval Dezhao Luo, Shaogang Gong, Jiabo Huang, Hailin Jin, Yang Liu† Conference on Artificial Intelligence (AAAI), 2025 [ PDF] [Project Page] [ Bibtex] |
|
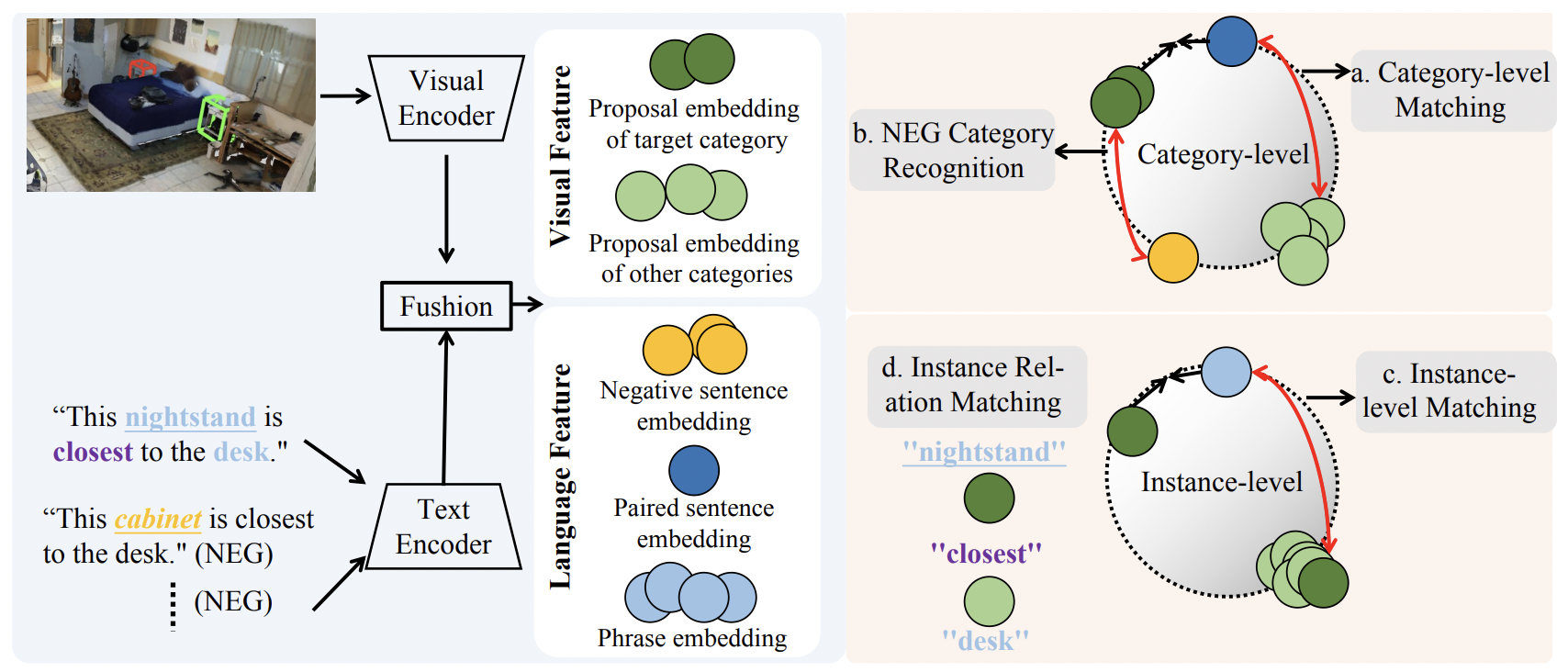
3D Weakly Supervised Visual Grounding at Category and Instance Levels Xiaoqi Li, Jiaming Liu, Yandong Guo, Hao Dong, Yang Liu† International Conference on Robotics and Automation (ICRA), 2025 [ PDF] [ Bibtex] |

|
Zero Shot Domain Adaptive Semantic Segmentation by Synthetic Data Generation and Progressive Adaptation Jun Luo, Zijing Zhao, Yang Liu† International Conference on Intelligent Robots and Systems(IROS), 2025 [ PDF] [ Code] [ Bibtex] |
|
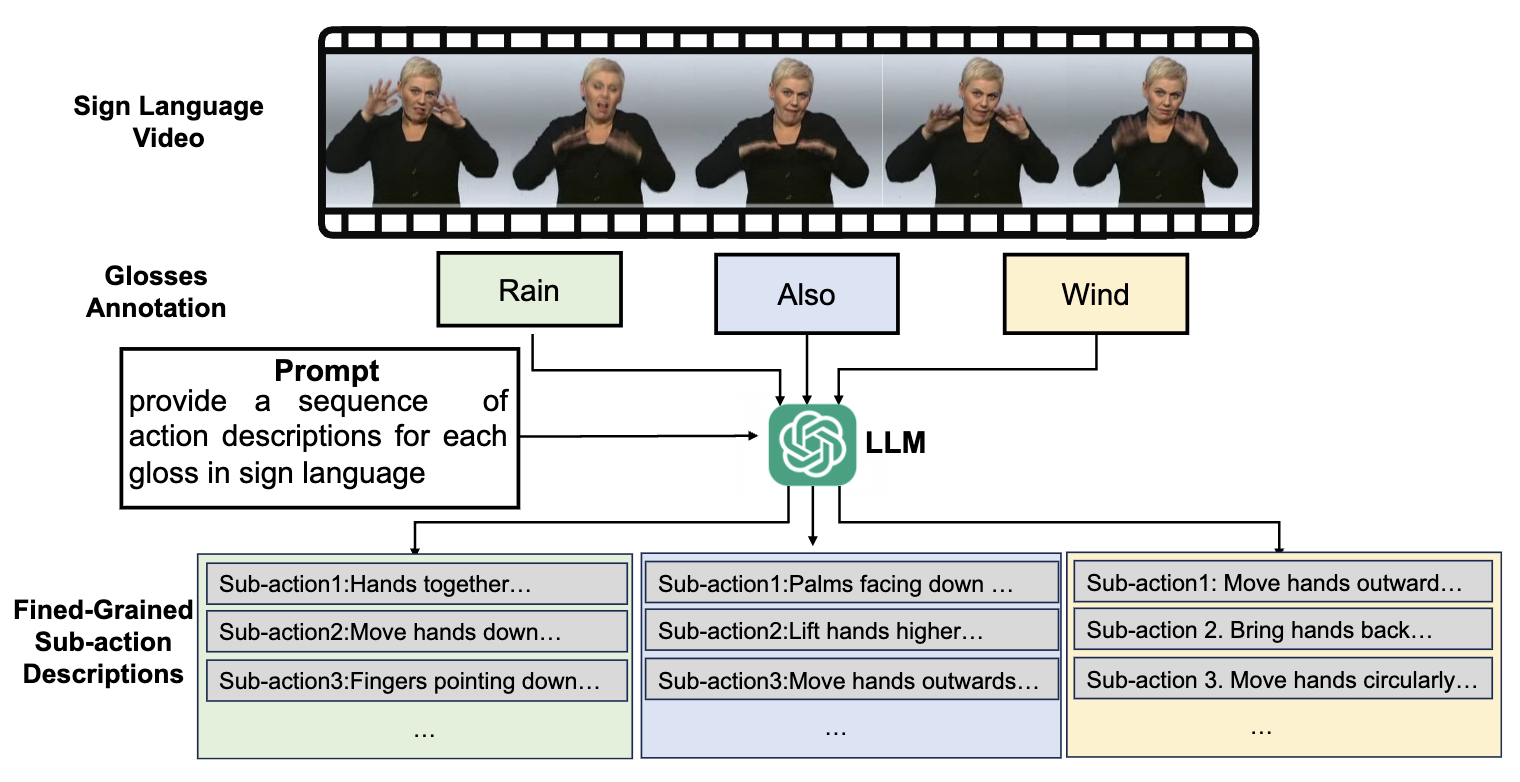
Hierarchical Sub-action Tree for Continuous Sign Language Recognition Dejie Yang, Zhu Xu, Xinjie Gao, Yang Liu† IEEE International Conference on Multimedia&Expo (ICME), 2025 [ PDF] [Project Page] [ Code] [ Bibtex] |

|
Semantic-Aware Human Object Interaction Image Generation Zhu Xu, Qingchao Chen, Yuxin Peng, Yang Liu† International Conference on Machine Learning (ICML), 2024 [ PDF] [Project Page] [Video] [ Code] [公众号] [ Bibtex] |

|
Training Free Video Temporal Grounding using Large-scale Pre-trained Models Minghang Zheng, Xinhao Cai, Qingchao Chen, Yuxin Peng, Yang Liu† European Conference on Computer Vision (ECCV), 2024 [ PDF] [Project Page] [Video] [ Code] [ Bibtex] |

|
Exploring Conditional Multi-Modal Prompts for Zero-shot HOI Detection Ting Lei, Shaofeng Yin, Yuxin Peng, Yang Liu† European Conference on Computer Vision (ECCV), 2024 [ PDF] [Project Page] [Video] [ Code] [公众号] [ Bibtex] |
|
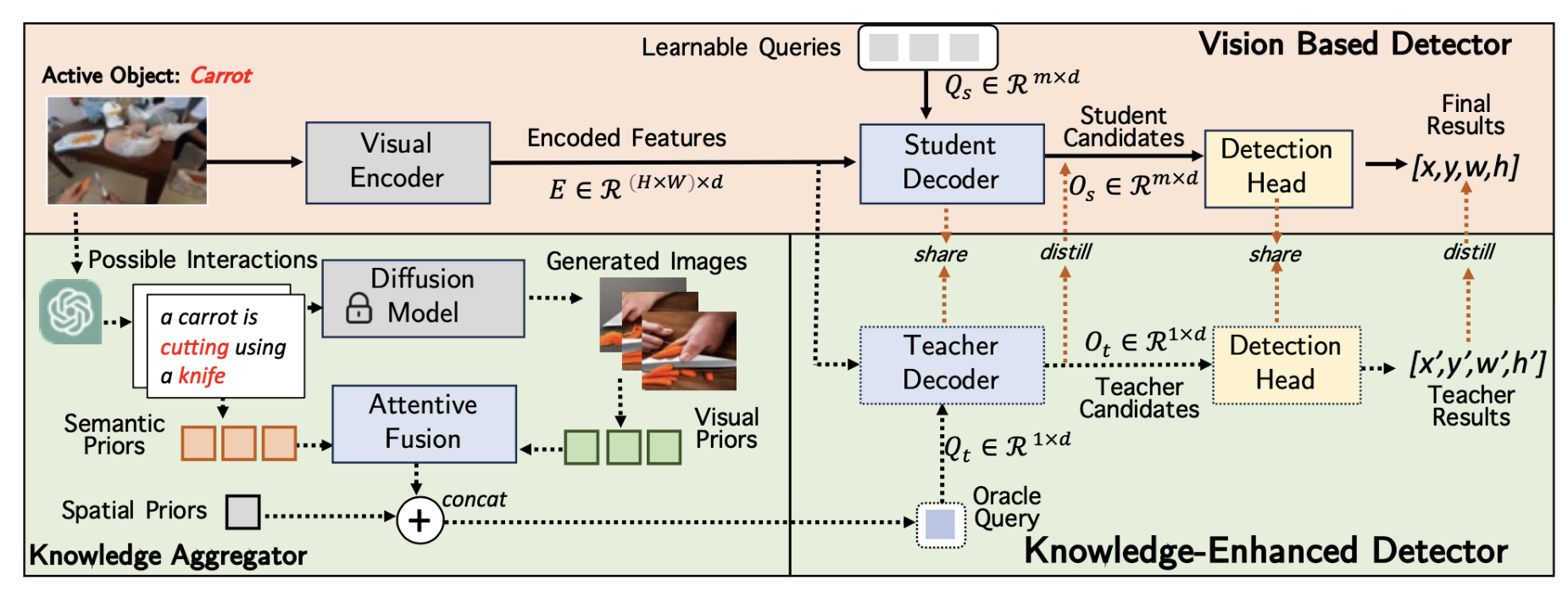
Active Object Detection with Knowledge Aggregation and Distillation from Large Models Dejie Yang, Yang Liu† IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 [ PDF] [Project Page] [Video] [ Code] [ Bibtex] |
|
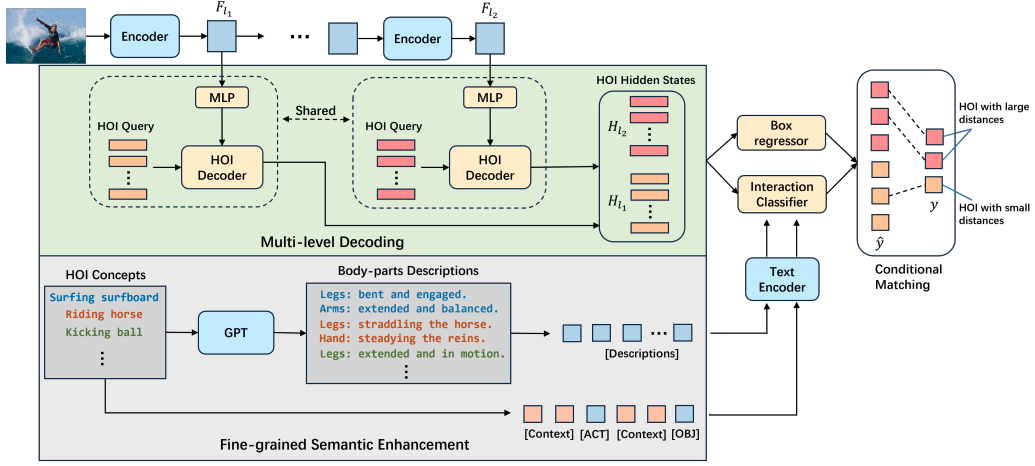
Exploring the Potential of Large Foundation Models for Open-Vocabulary HOI Detection Ting Lei, Shaofeng Yin, Yang Liu† IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 [ PDF] [Project Page] [Video] [ Code] [ Bibtex] |

|
OED: Towards One-stage End-to-End Dynamic Scene Graph Generation Guan Wang, Zhimin Li, Qingchao Chen, Yang Liu† IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 [ PDF] [Project Page] [Video] [ Code] [ Bibtex] |
|
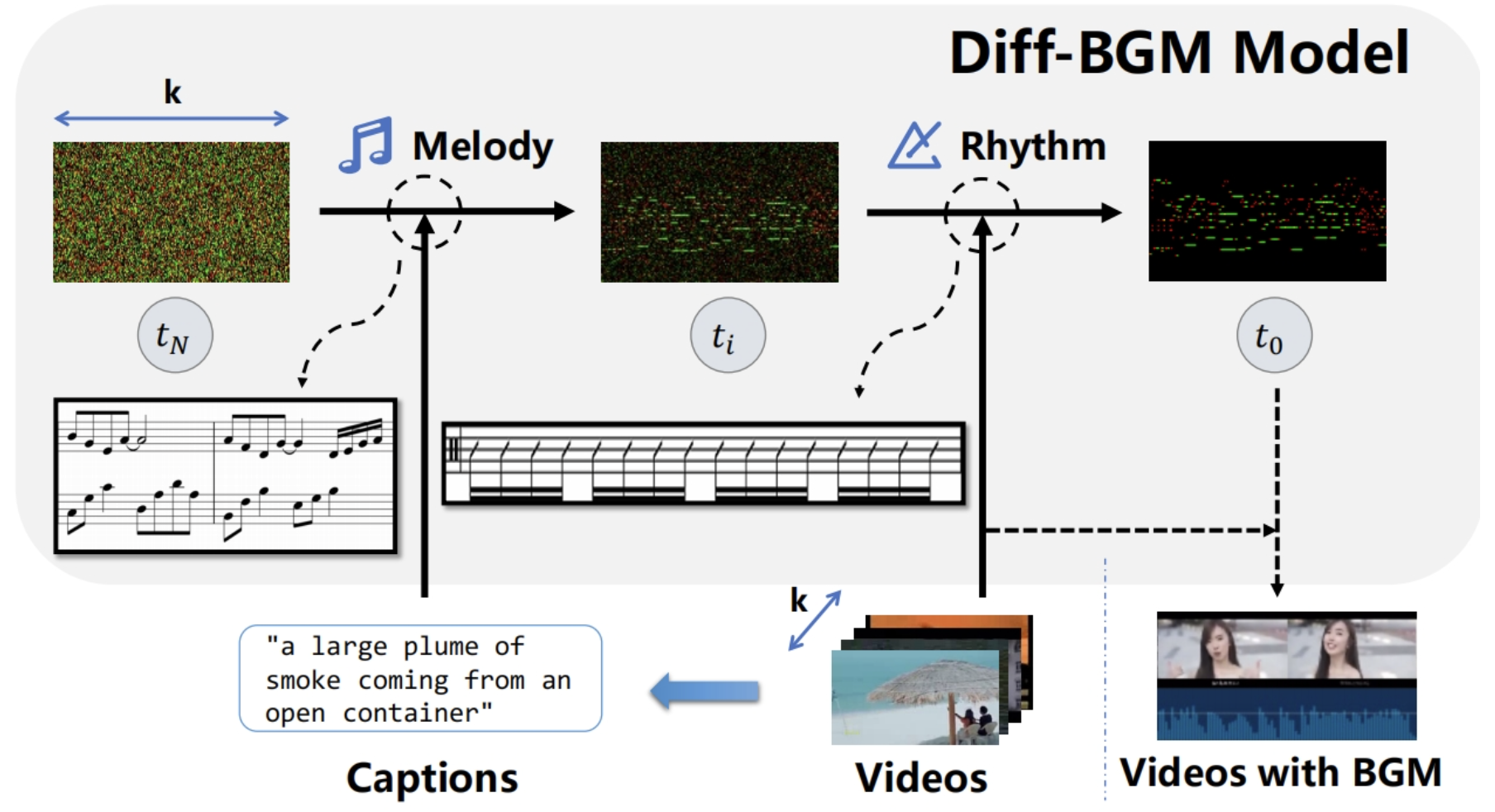
Diff-BGM: A Diffusion Model for Video Background Music Generation Sizhe Li, Yiming Qin, Minghang Zheng, Xin Jin, Yang Liu† IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 [ PDF] [Project Page] [Video] [ Code] [ Bibtex] |

|
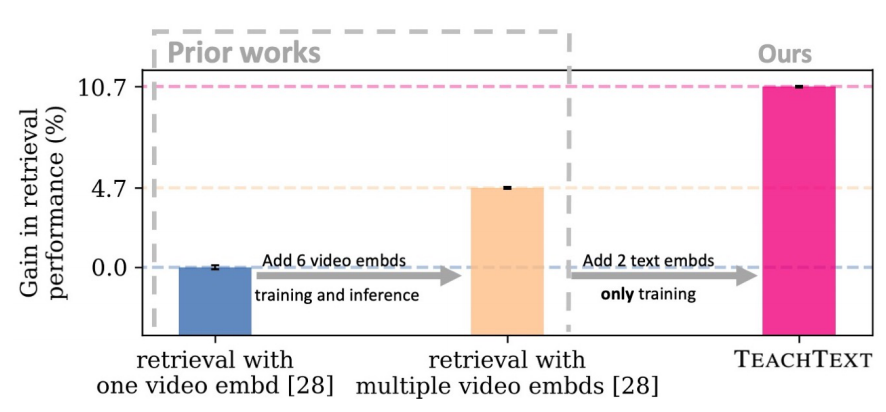
TeachText: CrossModal Text-Video Retrieval through Generalized Distillation Ioana Croitoru, Simion-Vlad Bogolin, Marius Leordeanuc, Hailin Jin, Andrew Zisserman, Yang Liu†, Samuel Albanie Artificial Intelligence Journal (AIJ), 2024 [ PDF] [Project Page] [Code] |
|
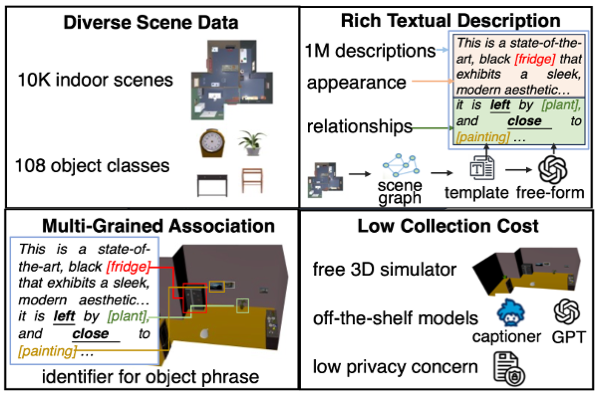
3D Vision and Language Pretraining with Large-Scale Synthetic Data Dejie Yang, Zhu Xu, Wentao Mo, Qingchao Chen, Siyuan Huang, Yang Liu† International Joint Conference on Artificial Intelligence (IJCAI), 2024 [ PDF] [Project Page] [Video] [ Code] [ Bibtex] |
|
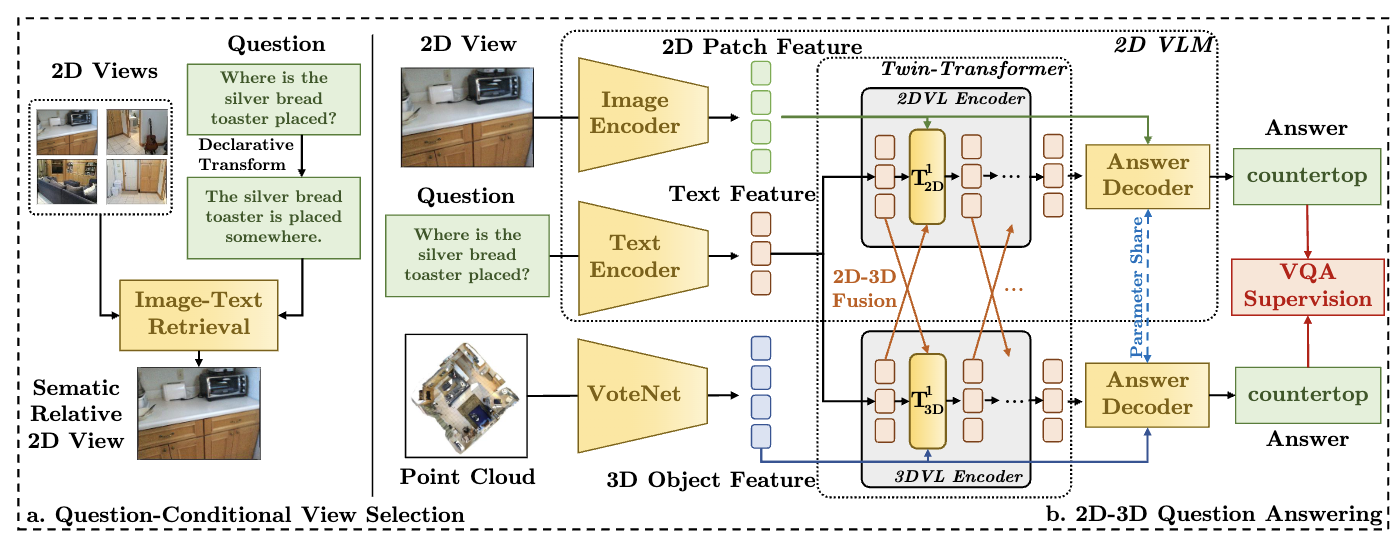
Bridging the Gap between 2D and 3D Visual Question Answering: A Fusion Approach for 3D VQA Wentao Mo, Yang Liu† Conference on Artificial Intelligence (AAAI), 2024 [ PDF] [Project Page] [ Code] [ Bibtex] |
|
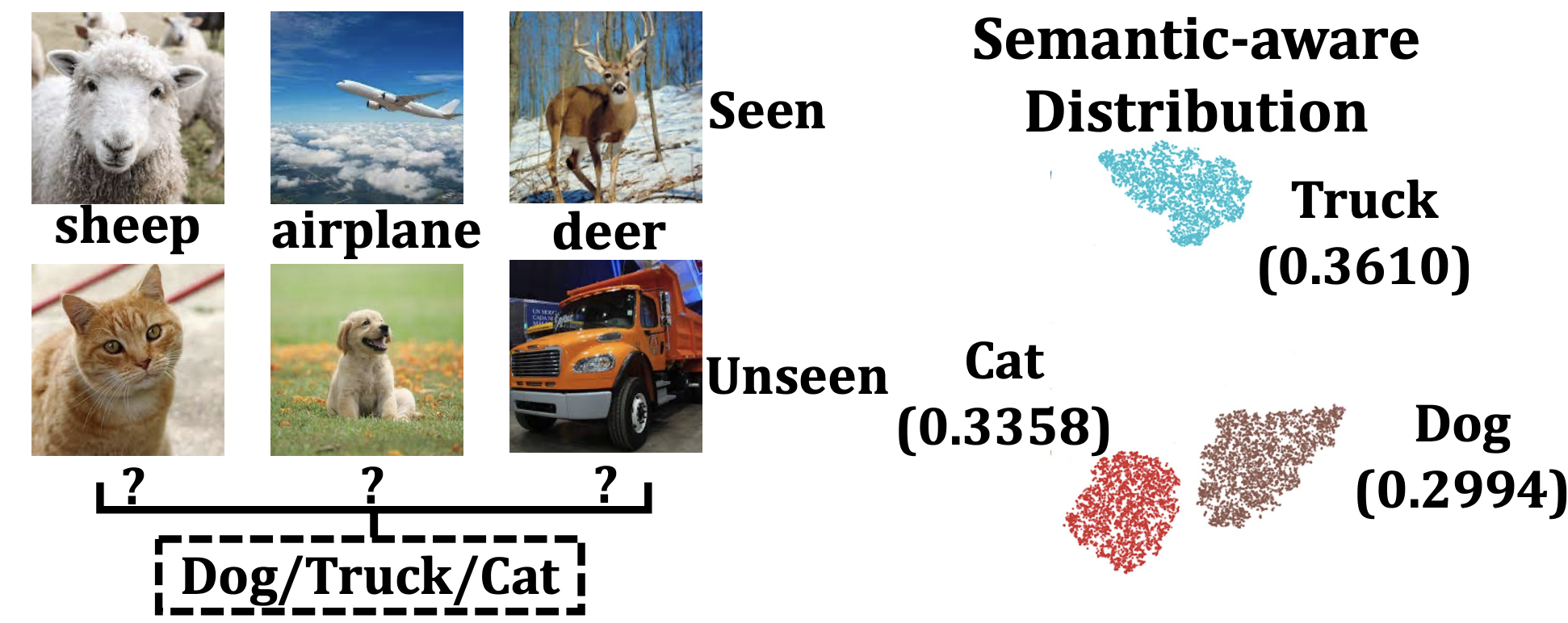
Semantic-Guided Novel Category Discovery Weishuai Wang, Ting Lei, Qingchao Chen, Yang Liu† Conference on Artificial Intelligence (AAAI), 2024 [ PDF] [Project Page] [Video] [ Code] [ Bibtex] |
|
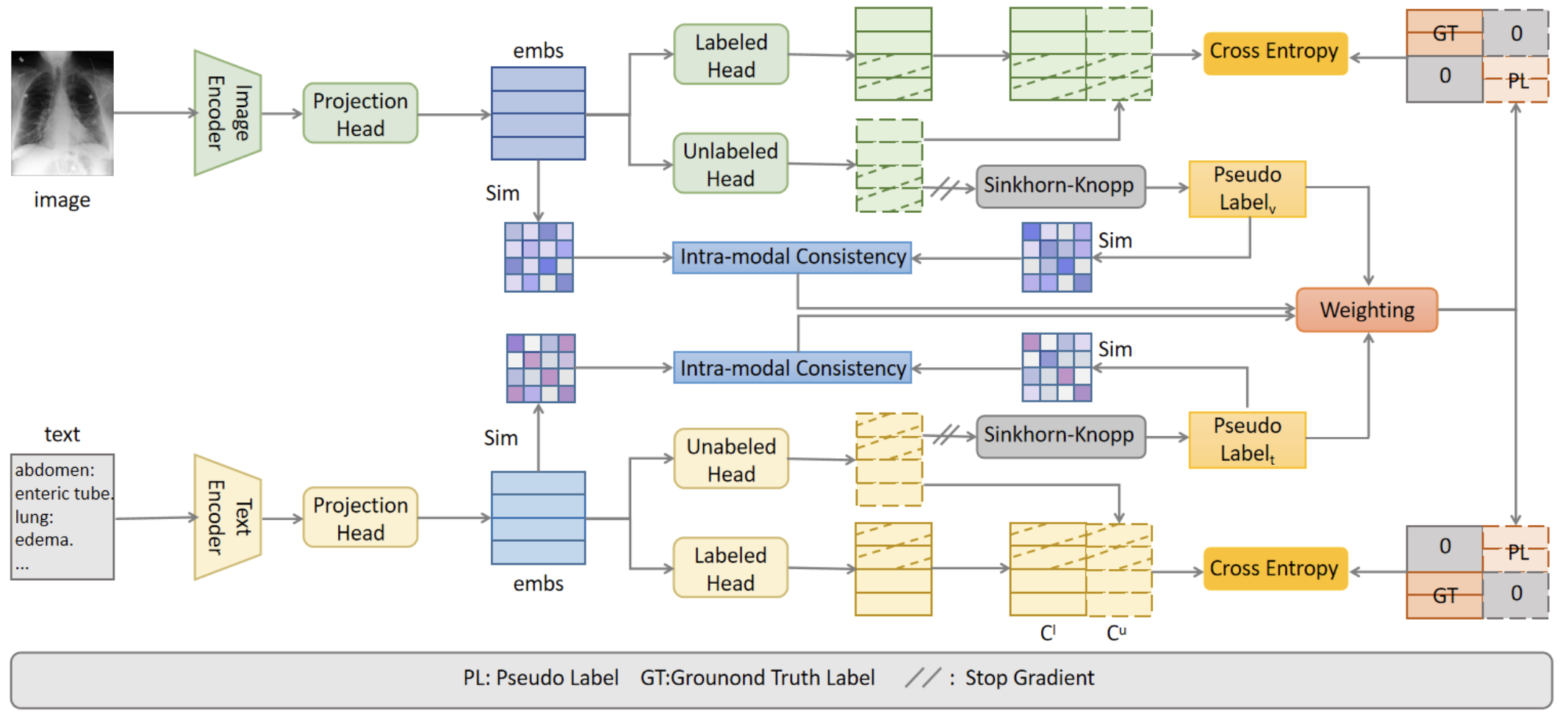
Novel Class Discovery in Chest X-Rays via Paired Images and Text Jiaying Zhou, Yang Liu, Qingchao Chen Conference on Artificial Intelligence (AAAI), 2024 [ PDF] [ Bibtex] |

|
ResVG: Enhancing Relation and Semantic Understanding in Multiple Instances for Visual Grounding Minghang Zheng, Jiahua Zhang, Qingchao Chen, Yuxin Peng, Yang Liu† ACM International Conference on Multimedia (ACM-MM), 2024 [ PDF] [Project Page] [Video] [ Code] [ Bibtex] |

|
RelScene: A Benchmark and baseline for Spatial Relations in text-driven 3D Scene Generation Zhaoda Ye, Xinhan Zheng, Yang Liu, Yuxin Peng ACM International Conference on Multimedia (ACM-MM), 2024 [ PDF] |

|
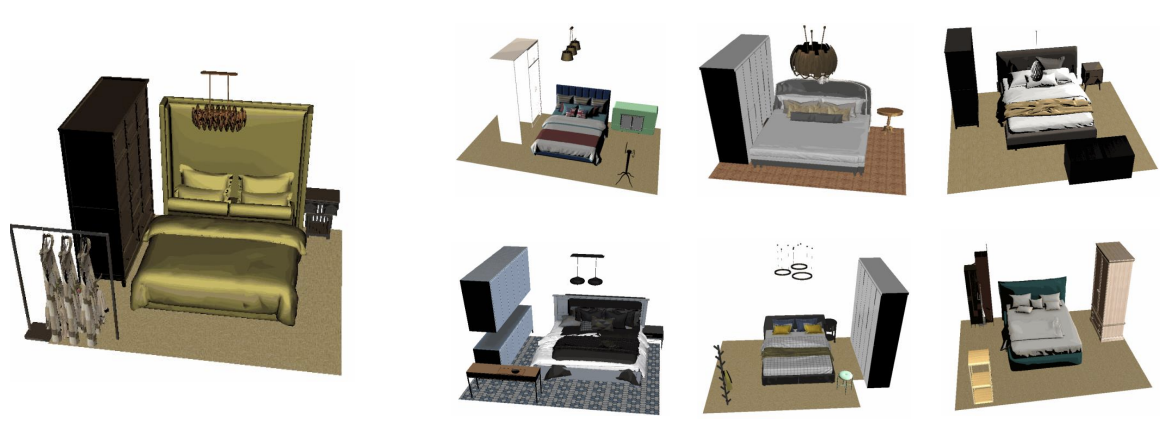
Efficient Temporal Extrapolation of Multimodal Large Language Models with Temporal Grounding Bridge Yuxuan Wang, Yueqian Wang, Pengfei Wu, Jianxin Liang, Dongyan Zhao, Yang Liu, Zilong Zheng Empirical Methods in Natural Language Processing (EMNLP), 2024 [ PDF] [ Code] [ Bibtex] |
|
MAAN: Memory-Augmented Auto-regressive Network for Text-driven 3D Indoor Scene Generation Zhaoda Ye, Yang Liu, Yuxin Peng IEEE Transactions on Multimedia (TMM), 2024 [ PDF] [ Bibtex] |
|
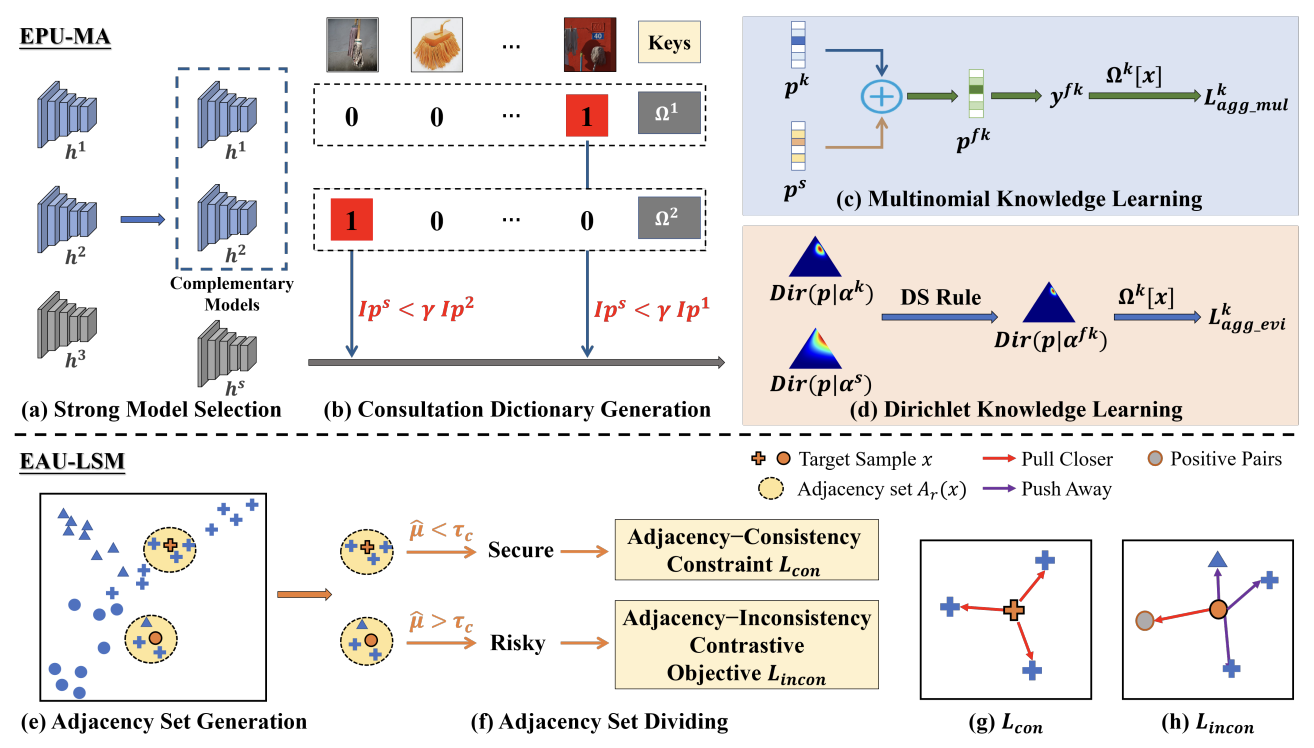
Evidential Multi-Source-Free Unsupervised Domain Adaptation Jiangbo Pei, Aidong Men, Yang Liu, Xiahai Zhuang, Qingchao Chen IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024 [ PDF] [ Code] [ Bibtex] |
|
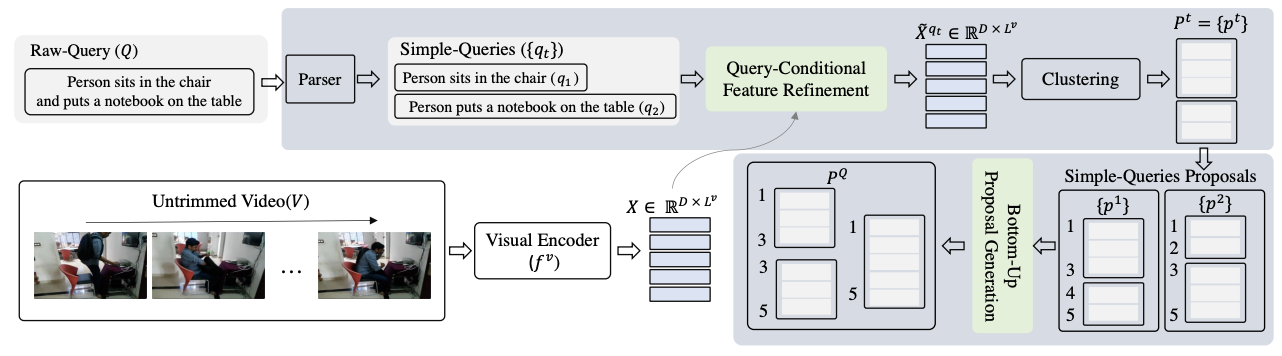
Zero-Shot Video Moment Retrieval from Frozen Vision-Language Models Dezhao Luo, Jiabo Huang, Shaogang Gong, Hailin Jin, Yang Liu† Winter Conference on Applications of Computer Vision (WACV), 2024 [ PDF] [ Bibtex] |
|
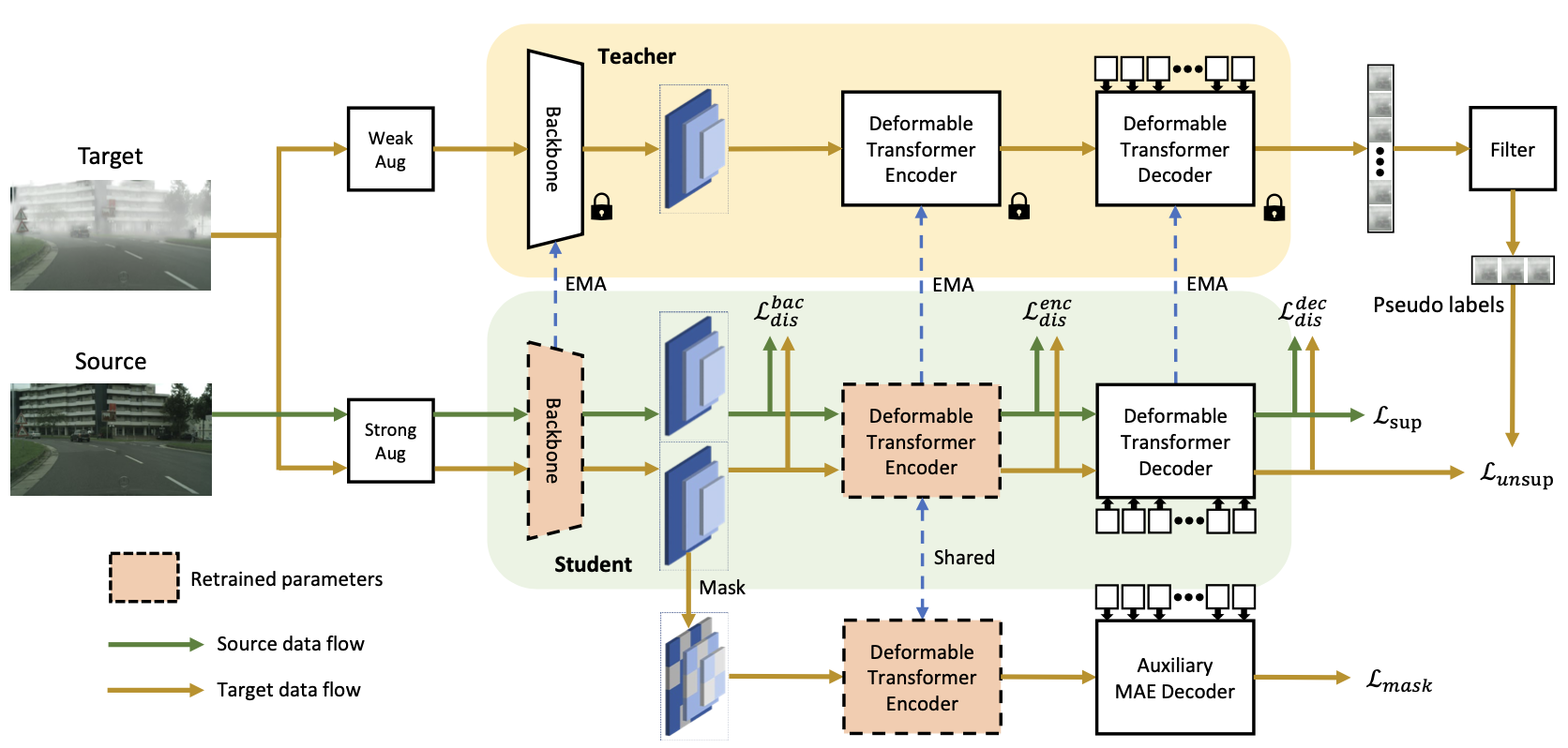
Masked Retraining Teacher-Student Framework for Domain Adaptive Object Detection Zijing Zhao, Sitong Wei, Qingchao Chen, Dehui Li, Yifan Yang, Yuxin Peng, Yang Liu† International Conference on Computer Vision (ICCV), 2023 [ PDF] [Supplementary Material] [Project Page] [Video] [ Code] [ Bibtex] |
|
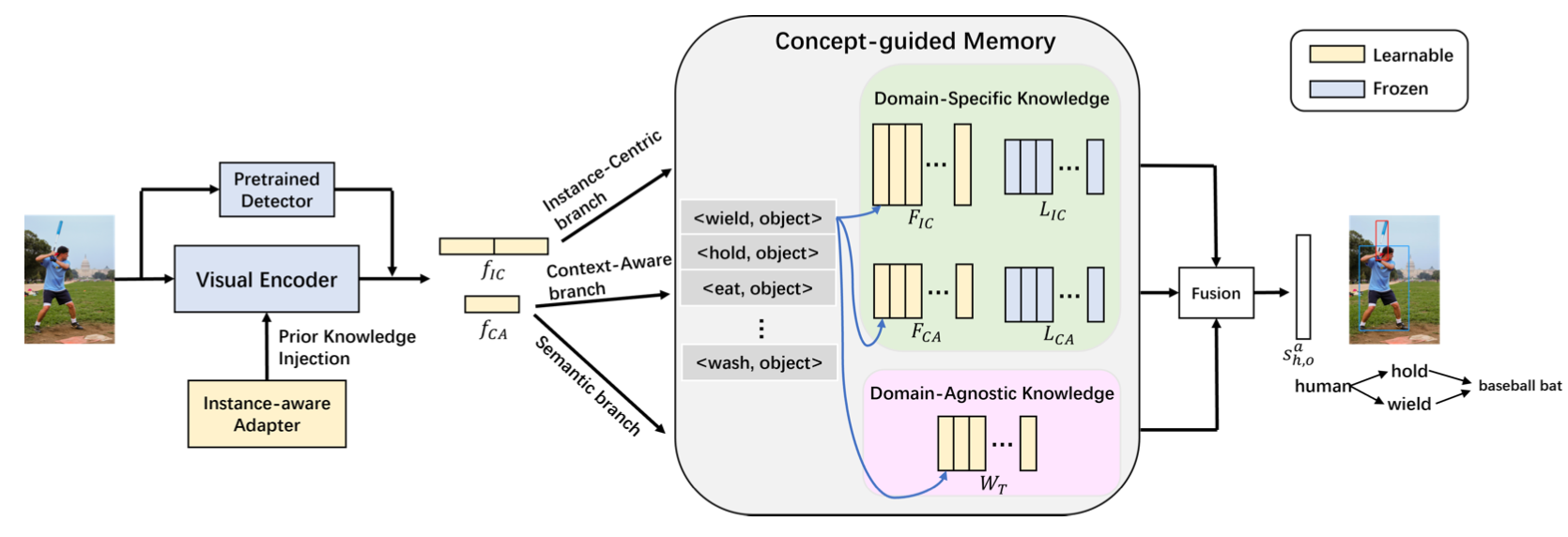
Efficient Adaptive Human-Object Interaction Detection with Concept-guided Memory Ting Lei, Fabian Caba, Qingchao Chen, Hailin Ji, Yuxin Peng, Yang Liu† International Conference on Computer Vision (ICCV), 2023 [ PDF] [Supplementary Material] [Project Page] [ Code] [ Bibtex] |
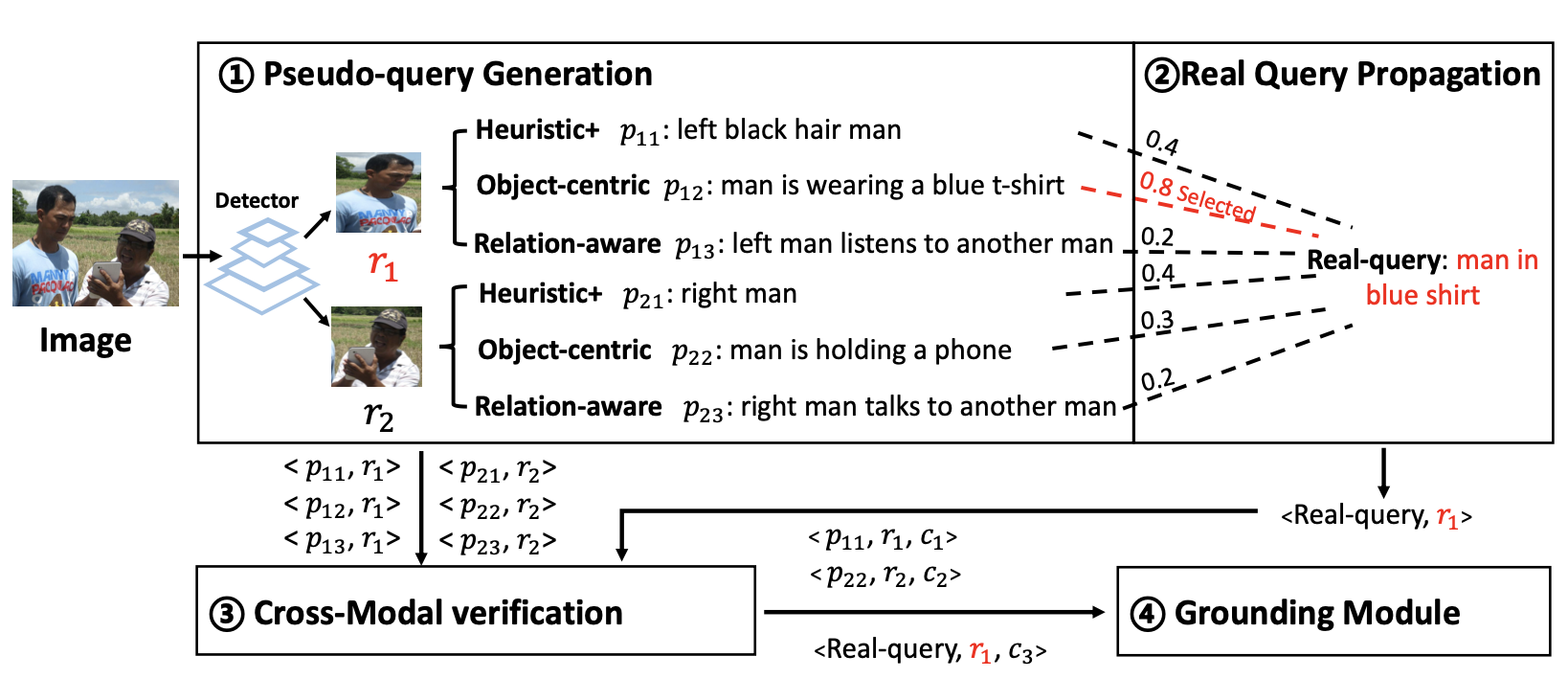
|
Confidence-aware Pseudo-label Learning for Weakly Supervised Visual Grounding Yang Liu,Jiahua Zhang, Qingchao Chen, Yuxin Peng International Conference on Computer Vision (ICCV), 2023 [ PDF] [Project Page] [ Code] [ Bibtex] |

|
Moment Detection in Long Tutorial Videos Ioana Croitoru, Simion-Vlad Bogolin, Samuel Albanie, Yang Liu, Zhaowen Wang, Seunghyun Yoon, Franck Dernoncourt, Hailin Jin, Trung Bui International Conference on Computer Vision (ICCV), 2023 [ PDF] [Supplementary Material] [ Dataset] [ Bibtex] |

|
Generating Structured Pseudo Labels for Noise-resistant Zero-shot Video Sentence Localization Minghang Zheng, Shaogang Gong, Hailin Jin, Yuxin Peng, Yang Liu† Annual Meeting of the Association for Computational Linguistics (ACL), 2023 [ PDF] [ Code] [ Bibtex] |
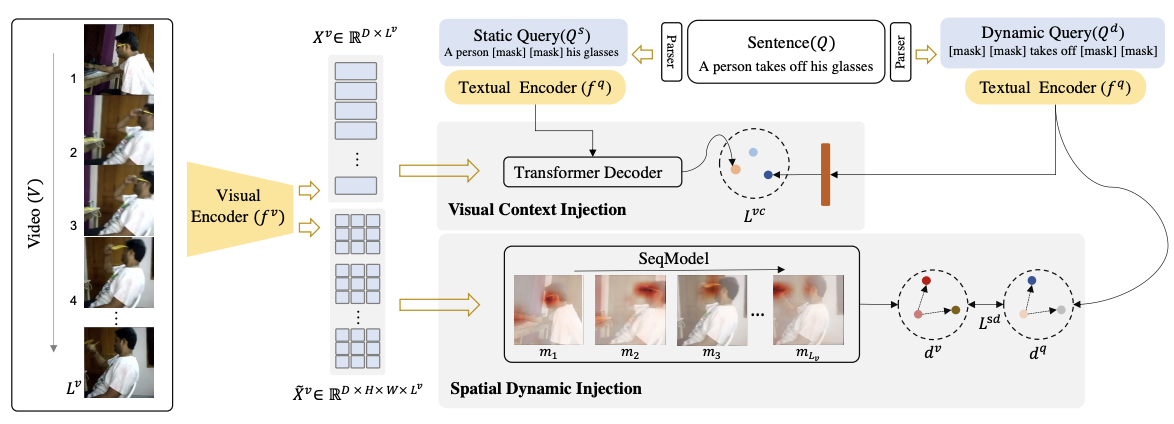
|
Towards Generalisable Video Moment Retrieval: Visual-Dynamic Injection to Image-Text Pre-Training Dezhao Luo, Jiabo Huang, Shaogang Gong, Hailin Jin, Yang Liu† IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023 [ PDF] [Supplementary Material] [ Bibtex] |
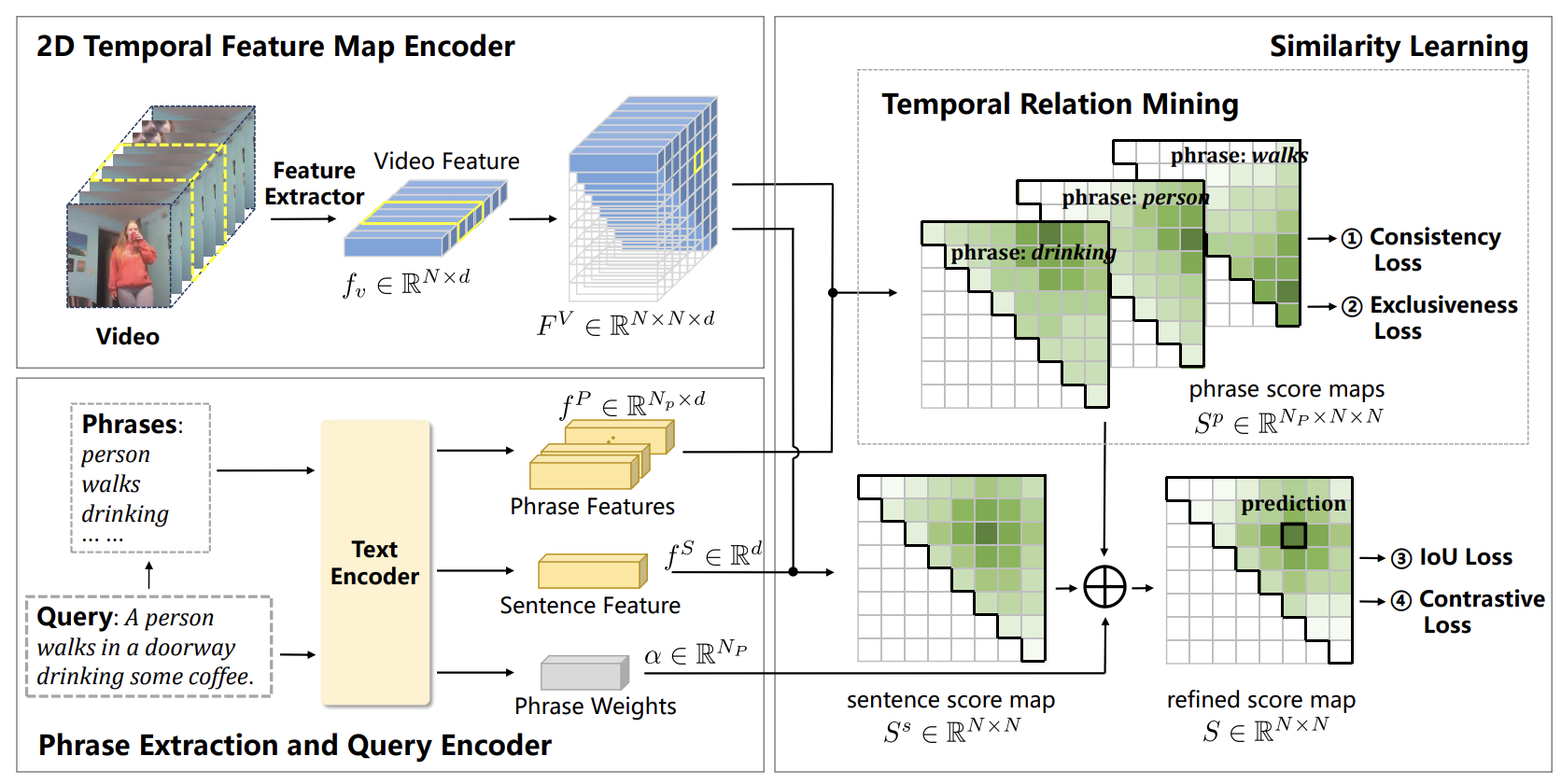
|
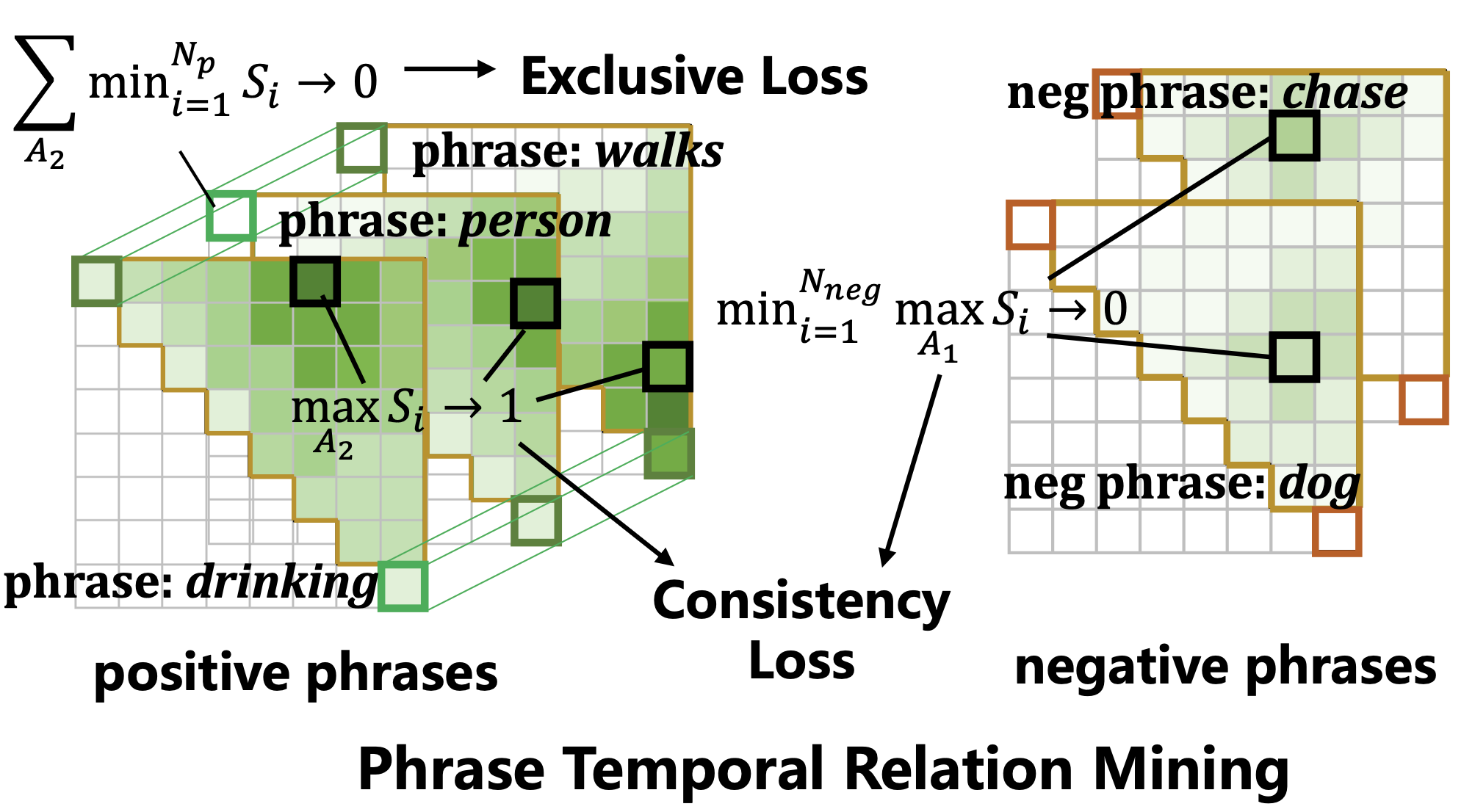
Phrase-level Temporal Relationship Mining for Temporal Sentence Localization Minghang Zheng, Sizhe Li, Qingchao Chen, Yuxin Peng, Yang Liu† Conference on Artificial Intelligence (AAAI), 2023 [ PDF] [ Code] [ Bibtex] |
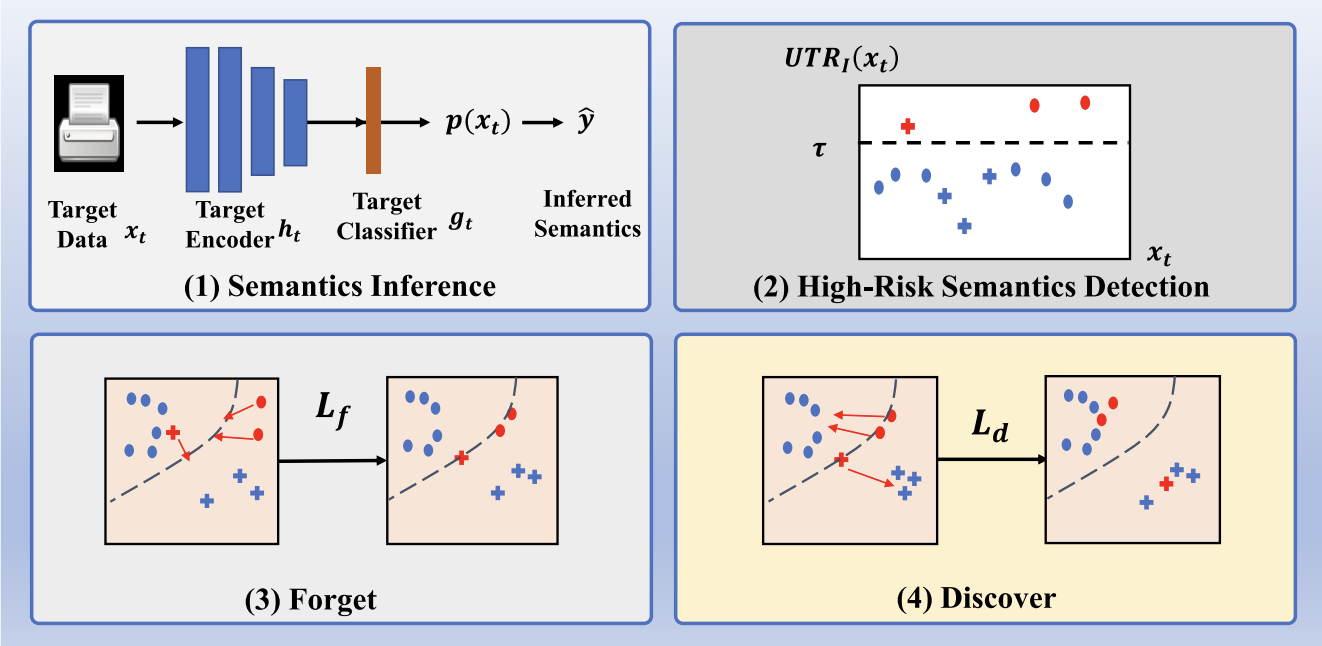
|
Uncertainty-induced transferability representation for source-free unsupervised domain adaptation Jiangbo Pei, Zhuqing Jiang, Aidong Men, Liang Chen, Yang Liu,Qingchao Chen IEEE Transactions on Image Processing (TIP), 2023 [ PDF] [ Code] [ Bibtex] |
|
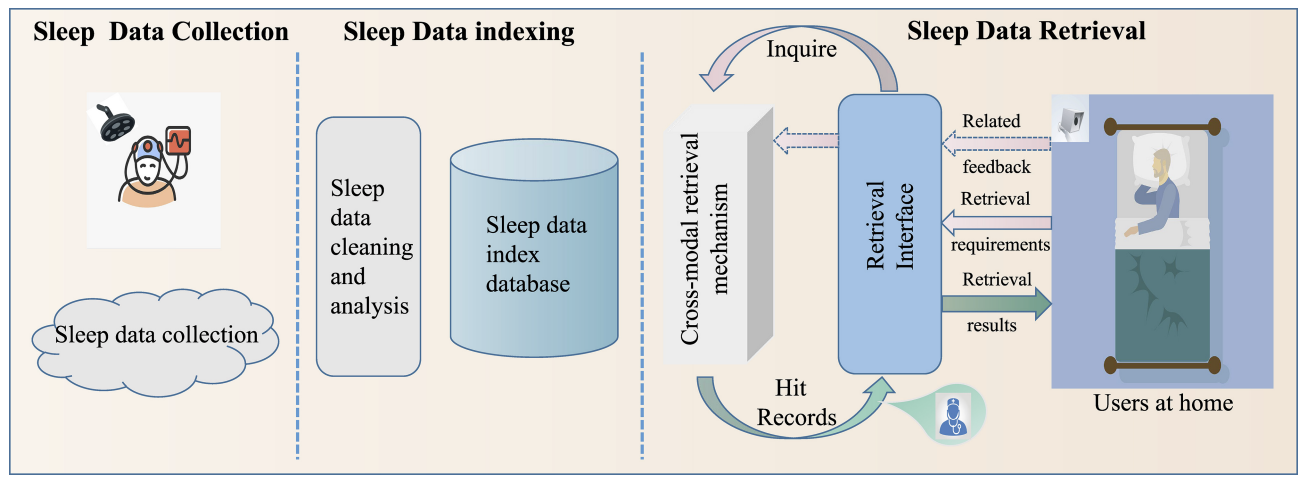
IoT-V2E: An Uncertainty-Aware Cross-Modal Hashing Retrieval Between Infrared-Videos and EEGs for Automated Sleep State Analysis Jianan Han , Aidong Men, Yang Liu, Ziming Yao, Shaoxing Zhang, Yan Yan, Qingchao Chen IEEE Internet of Things Journal, 2023 [ PDF] [ Code] [ Bibtex] |
|
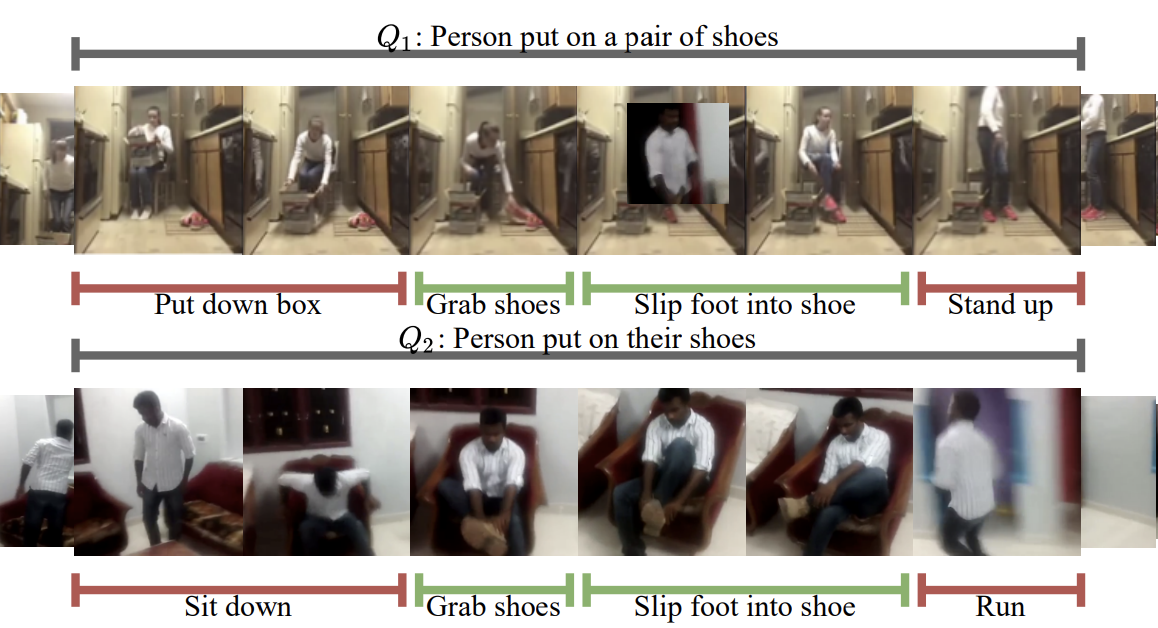
Video Activity Localisation with Uncertainties in Temporal Boundary Jiabo Huang, Hailin Jin, Shaogang Gong, Yang Liu† European Conference on Computer Vision (ECCV), 2022 [ PDF] [Supplementary Material] [ Code] |
|
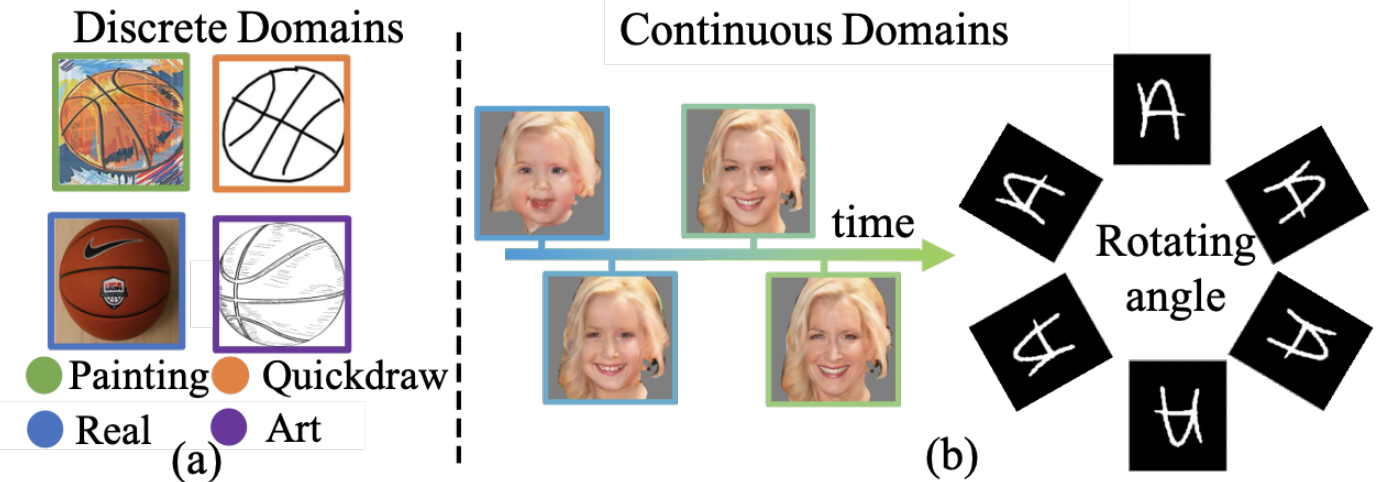
Delving into the Continuous Domain Adaptation Yinsong Xu, Zhuqing Jiang, Aidong Men, Yang Liu,Qingchao Chen ACM International Conference on Multimedia (ACM-MM), 2022 [ PDF] [ Bibtex] |
|
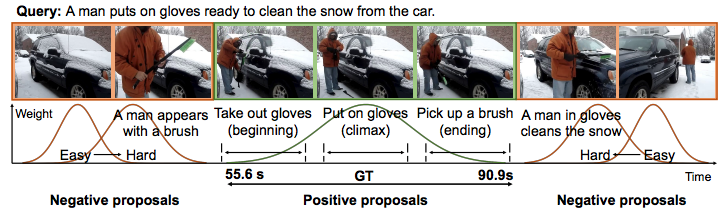
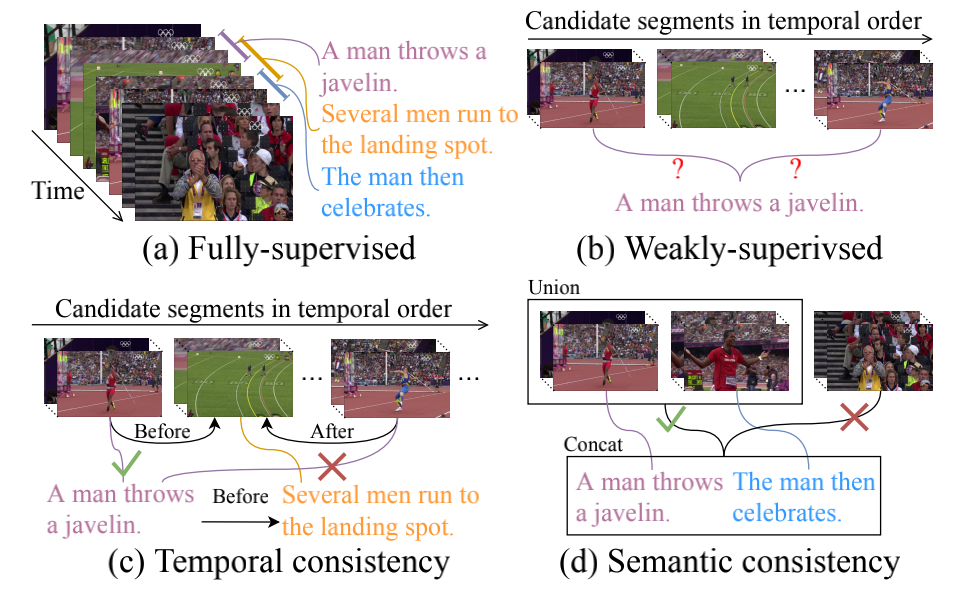
Weakly Supervised Temporal Sentence Grounding with Gaussian-based Contrastive Proposal Learning Minghang Zheng, Yanjie Huang, Qingchao Chen, Yuxin Peng, Yang Liu† IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [ PDF] [Project Page] [Code] [ Bibtex] |
|
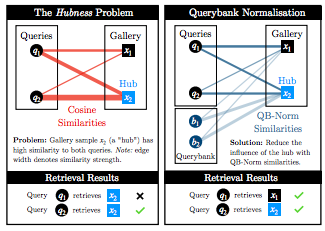
Cross Modal Retrieval with Querybank Normalisation Simion-Vlad Bogolin, Ioana Croitoru, Hailin Jin, Yang Liu†, Samuel Albanie† IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [ PDF] [Project Page] [Code] [ Bibtex] |
|
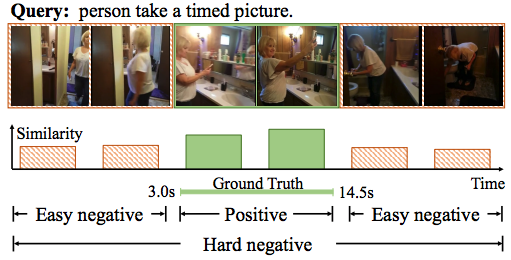
Weakly Supervised Video Moment Localization with Contrastive Negative Sample Mining Minghang Zheng, Yanjie Huang, Qingchao Chen, Yang Liu† Conference on Artificial Intelligence (AAAI), 2022 [ PDF] [Project Page] [Code] [ Bibtex] |
|
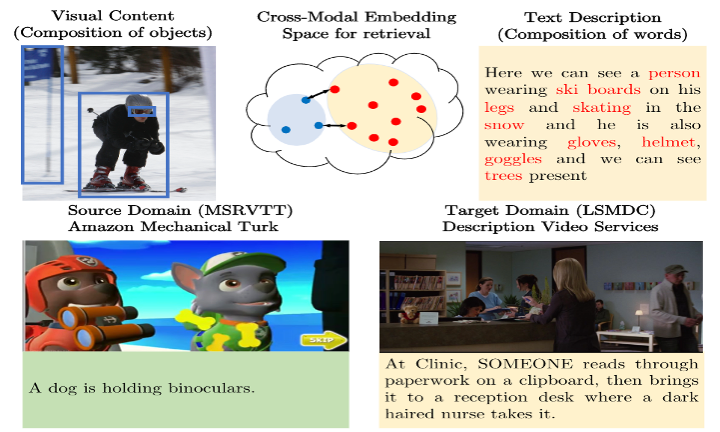
TeachText: CrossModal Generalized Distillation for Text-Video Retrieval Ioana Croitoru, Simion-Vlad Bogolin, Marius Leordeanu, Hailin Jin, Andrew Zisserman, Samuel Albanie, Yang Liu† International Conference on Computer Vision (ICCV), 2021 [ PDF] [Project Page] [Code] [ Bibtex] |
|
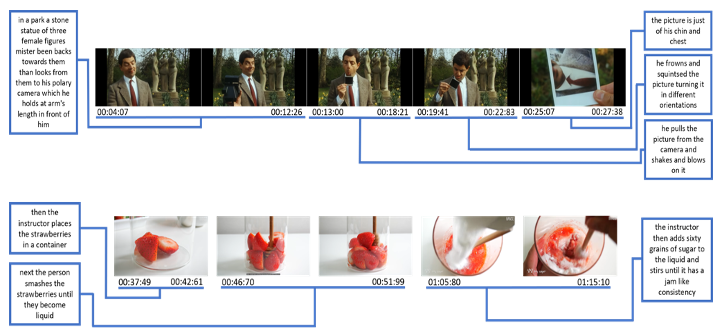
Cross-Sentence Temporal and Semantic Relations in Video Activity Localisation Jiabo Huang, Yang Liu†, Shaogang Gong, Hailin Jin International Conference on Computer Vision (ICCV), 2021 [ PDF] [ Bibtex] |
|
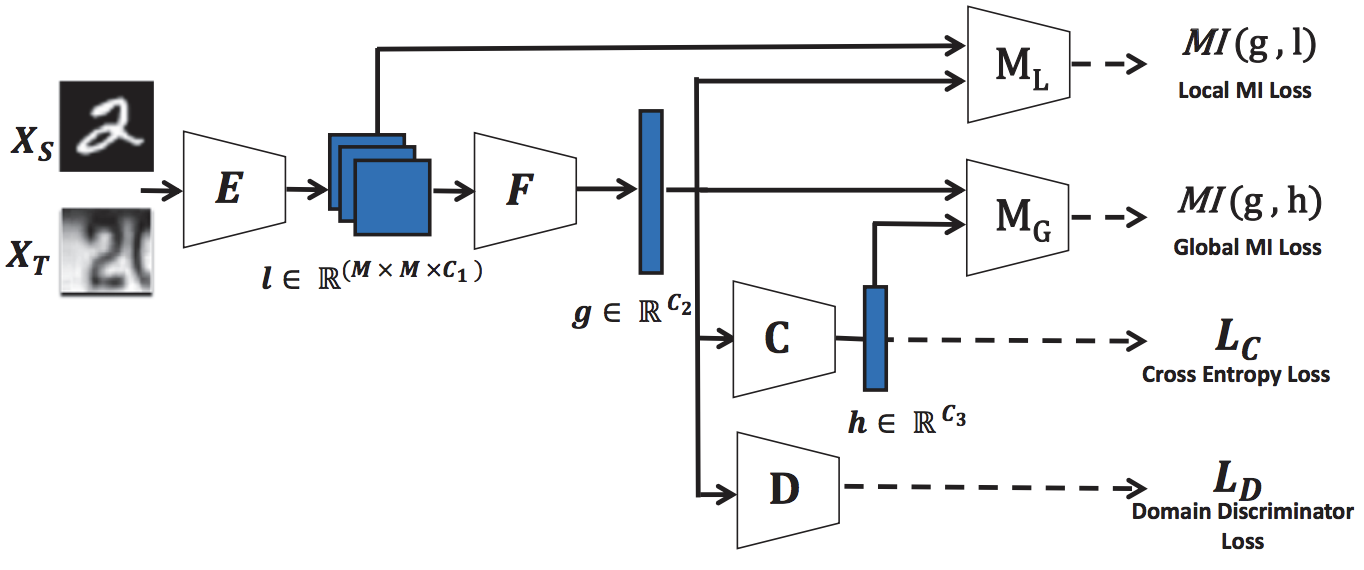
Adaptive Cross-Modal Prototypes for Cross-Domain Visual-Language Retrieval Yang Liu*, Qingchao Chen*, Samuel Albanie IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021 [pdf] [Bibtex] |

|
Mind-the-Gap! Unsupervised Domain Adaptation for Text-Video Retrieval Qingchao Chen*, Yang Liu*, Samuel Albanie Conference on Artificial Intelligence (AAAI), 2021 [pdf] [Bibtex] |
|
QuerYD: A video dataset with high-quality textual and audio narrations Andreea-Maria Oncescu, Joao F. Henriques, Yang Liu, Andrew Zisserman, Samuel Albanie IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021 [pdf] [Project Page ] [Audio Description Service ] [Bibtex] |

|
Amplifying Key Cues for Human-Object-Interaction Detection Yang Liu, Qingchao Chen, and Andrew Zisserman European Conference on Computer Vision (ECCV), 2020 [ PDF] [Supplementary Material] [Project Page] [Video] [ Bibtex] |
|
Structure-Aware Feature Fusion for Unsupervised Domain Adaptation Qingchao Chen*, Yang Liu* Conference on Artificial Intelligence (AAAI), 2020 [PDF] [Bibtex] |
|
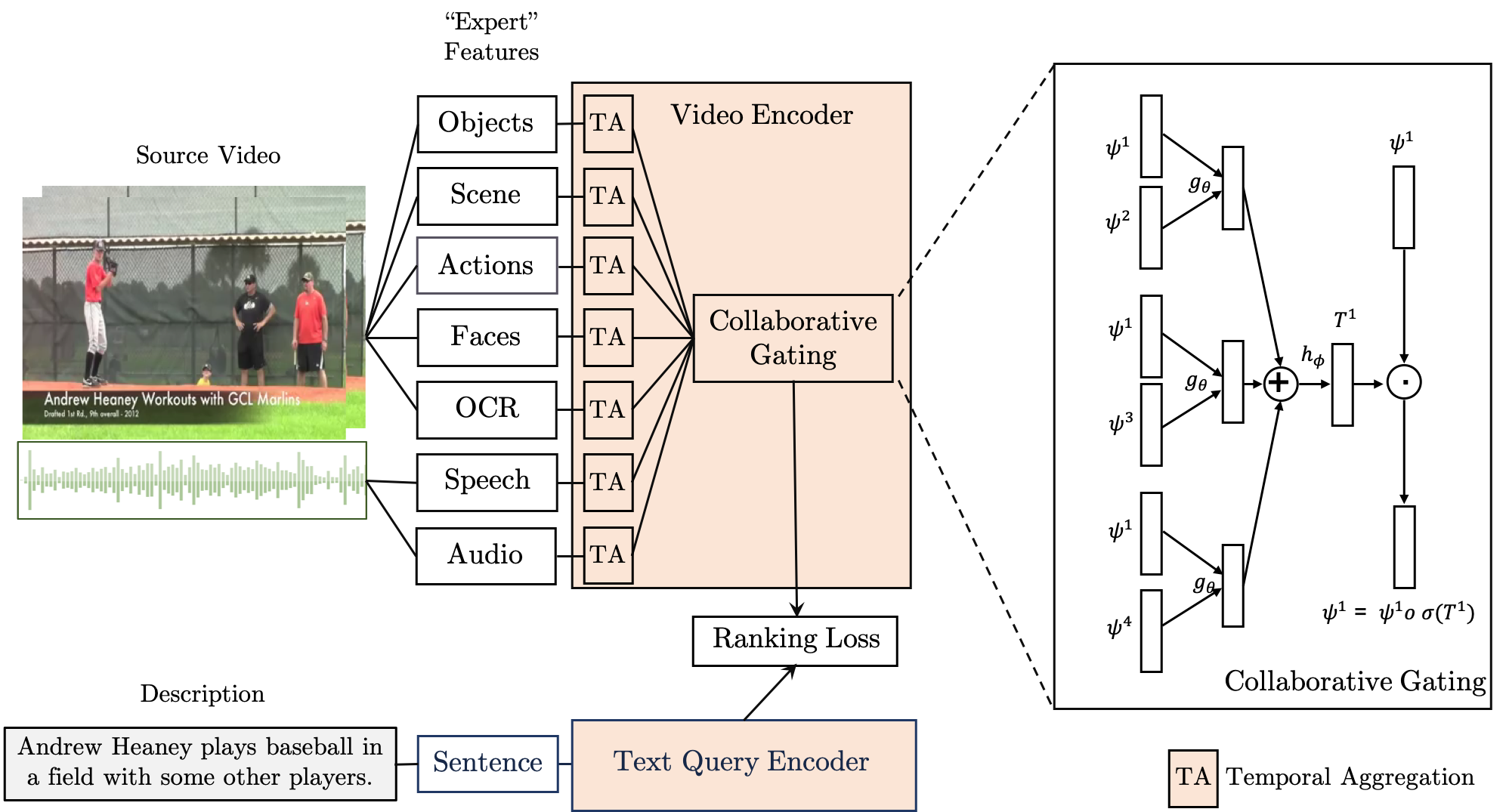
Use what you have: Video retrieval using representations from collaborative experts Yang Liu*, Samual Albanie*, Arsha Nagrani, and Andrew Zisserman British Machine Vision Conference (BMVC), 2019 [ PDF] [Project Page] [Code] [Challenge] [Challenge Report] [ Bibtex] |

|
Synthetically Supervised Feature Learning for Scene Text Recognition Yang Liu, Zhaowen Wang, Hailin Jin, and Ian Wassell European Conference on Computer Vision (ECCV), 2018 [ PDF] [ Bibtex] |
|
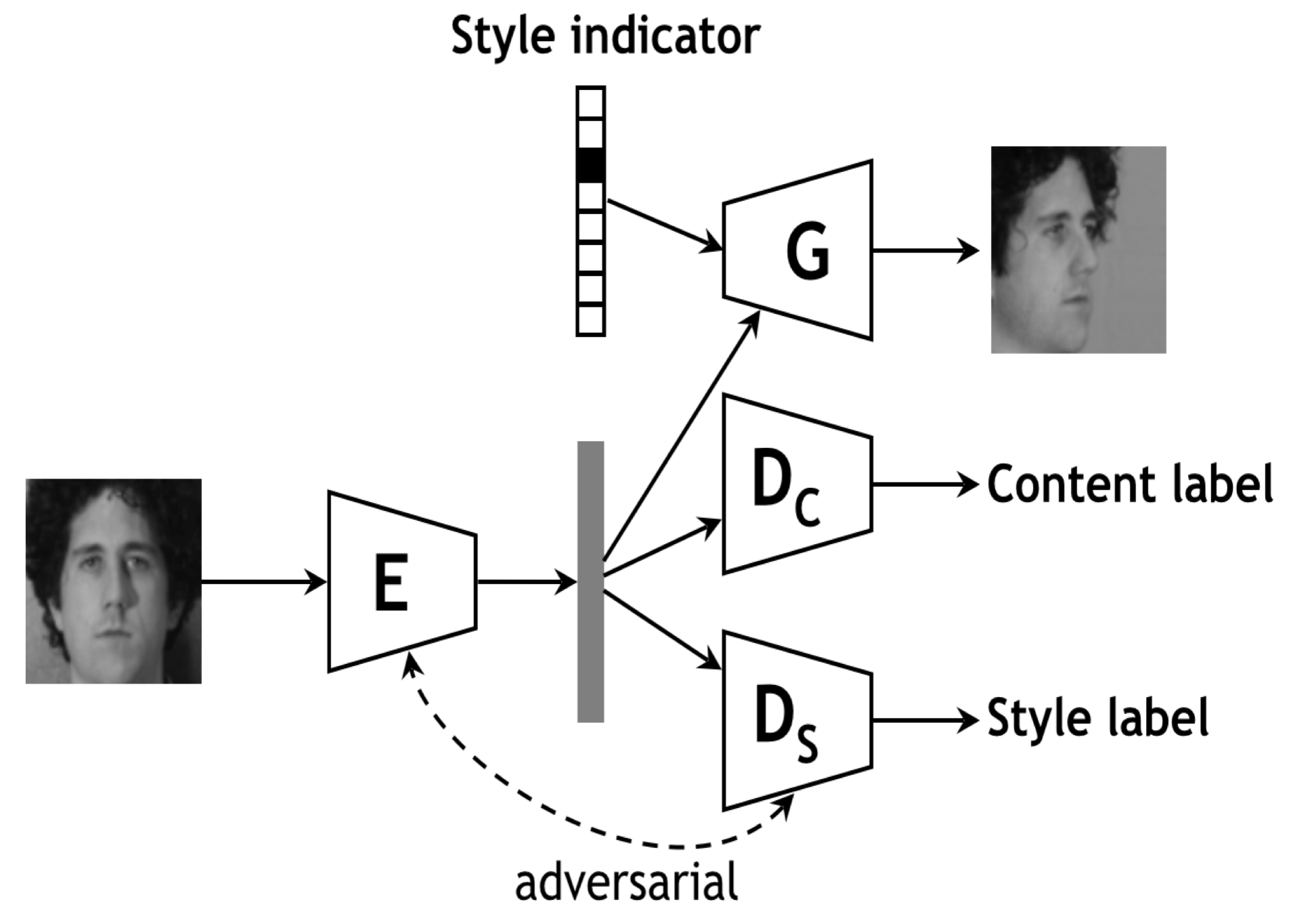
Multi-Task Adversarial Network for Disentangled Feature Learning Yang Liu, Zhaowen Wang, Hailin Jin, and Ian Wassell IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018 [ PDF] [ Bibtex] |
|
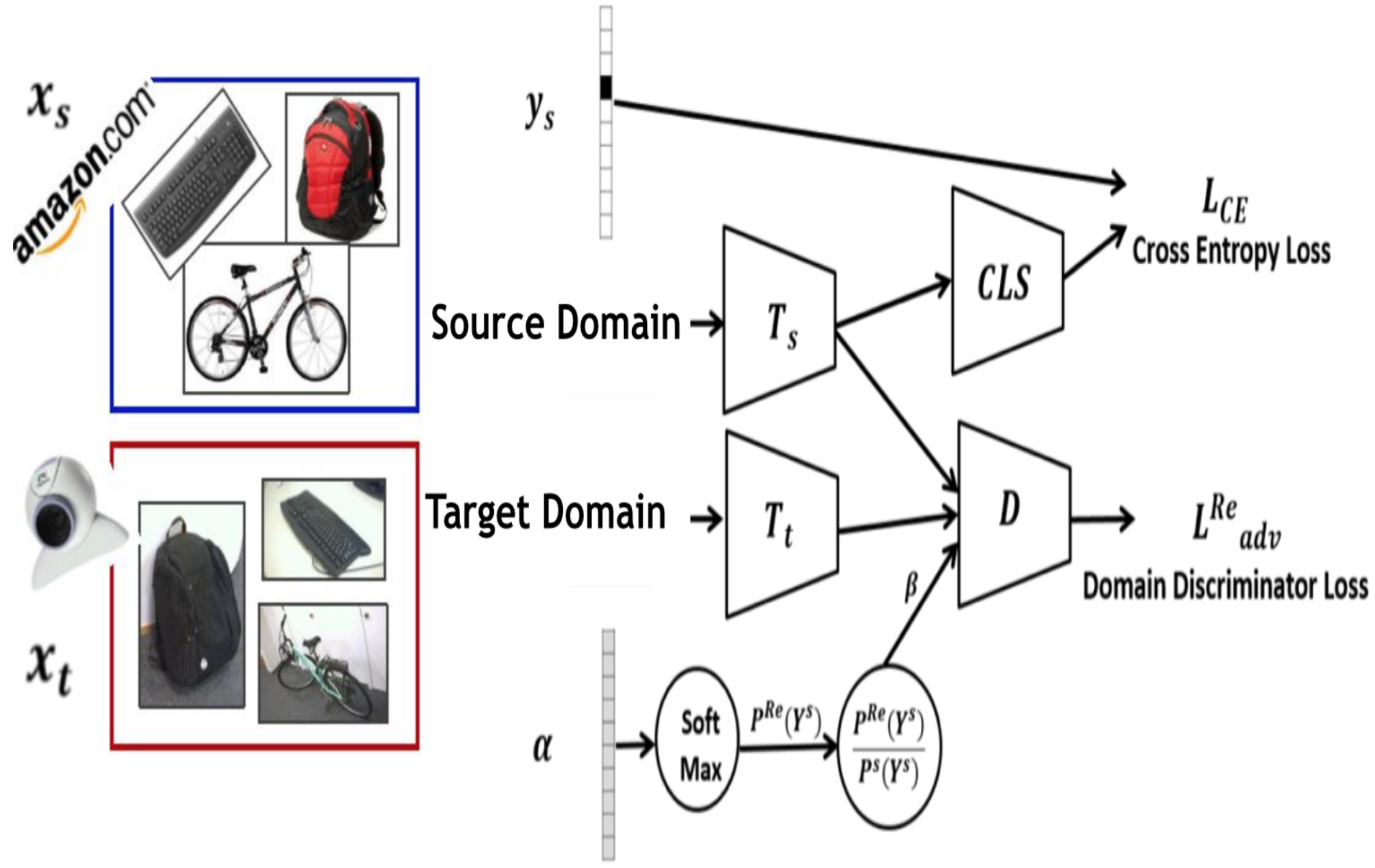
Re-weighted Adversarial Adaptation Network for Unsupervised Domain Adaptation Qingchao Chen*, Yang Liu*, Zhaowen Wang, Ian Wassell and Kevin Chetty IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018 [ PDF] [ Bibtex] |
|
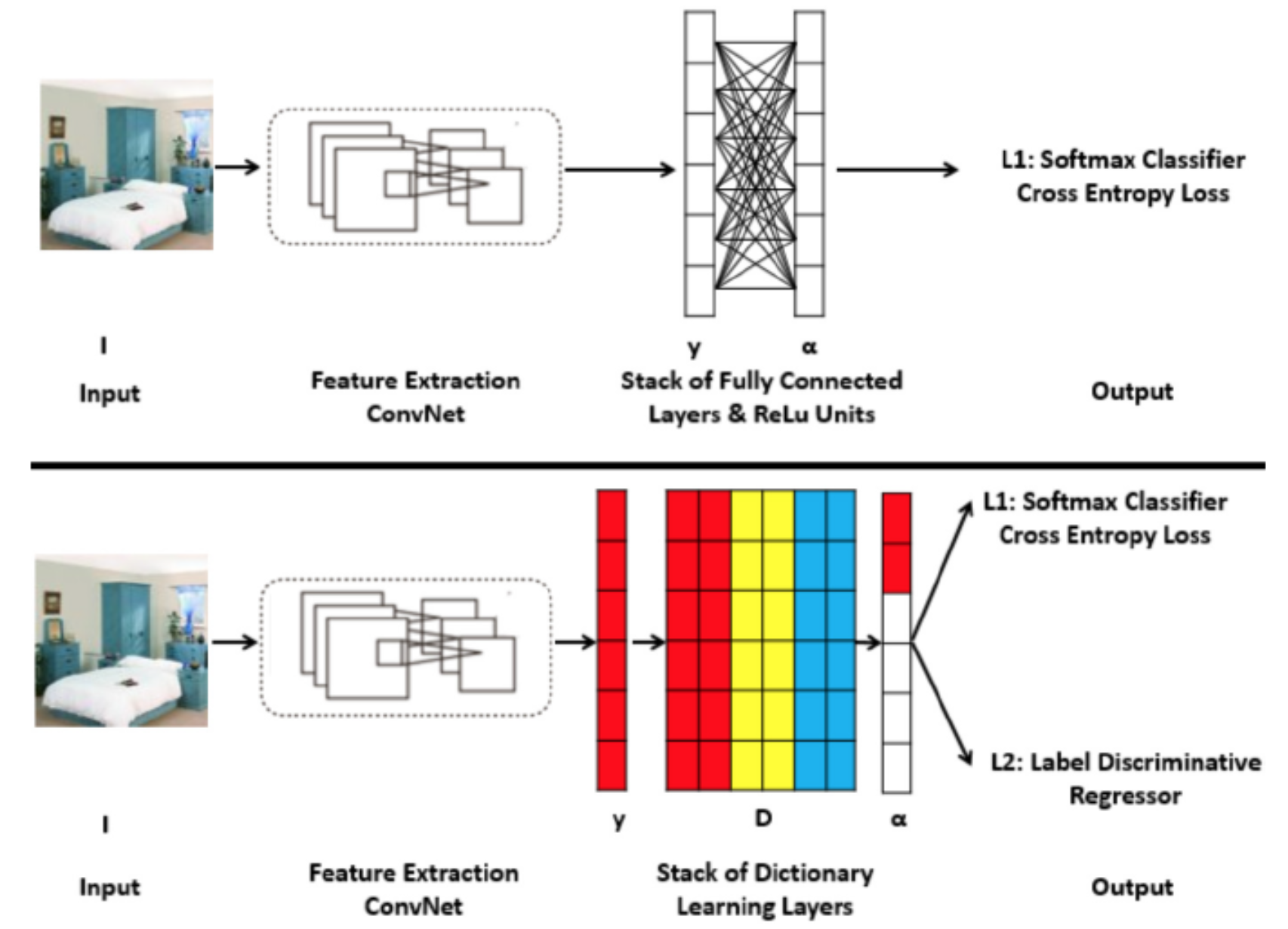
Discriminant Dictionary Learning meets CNN in Scene Recognition Yang Liu, Qingchao Chen, Wei Chen and Ian Wassell Conference on Artificial Intelligence (AAAI), 2018 [PDF] [Bibtex] |
|
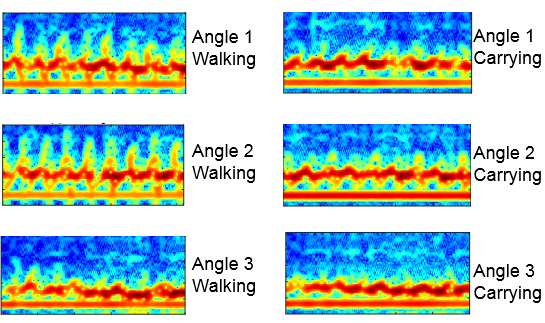
Joint fall and aspect angle recognition using fine-grained micro-Doppler classification Qingchao Chen, Matthiew Ritchie, Yang Liu, Kevin Chetty, Karl Woodbridge, IEEE Radar Conference (RadarConf), 2017 [PDF] [DOI] [Bibtex] |

|
Simultaneous Bayesian Sparse Approximation With Structured Sparse Models Wei Chen, David Wipf, Yu Wang, Yang Liu and Ian Wassell IEEE Transactions on Signal Processing (TIP), 2016 [PDF] [DOI] [Bibtex] |
|
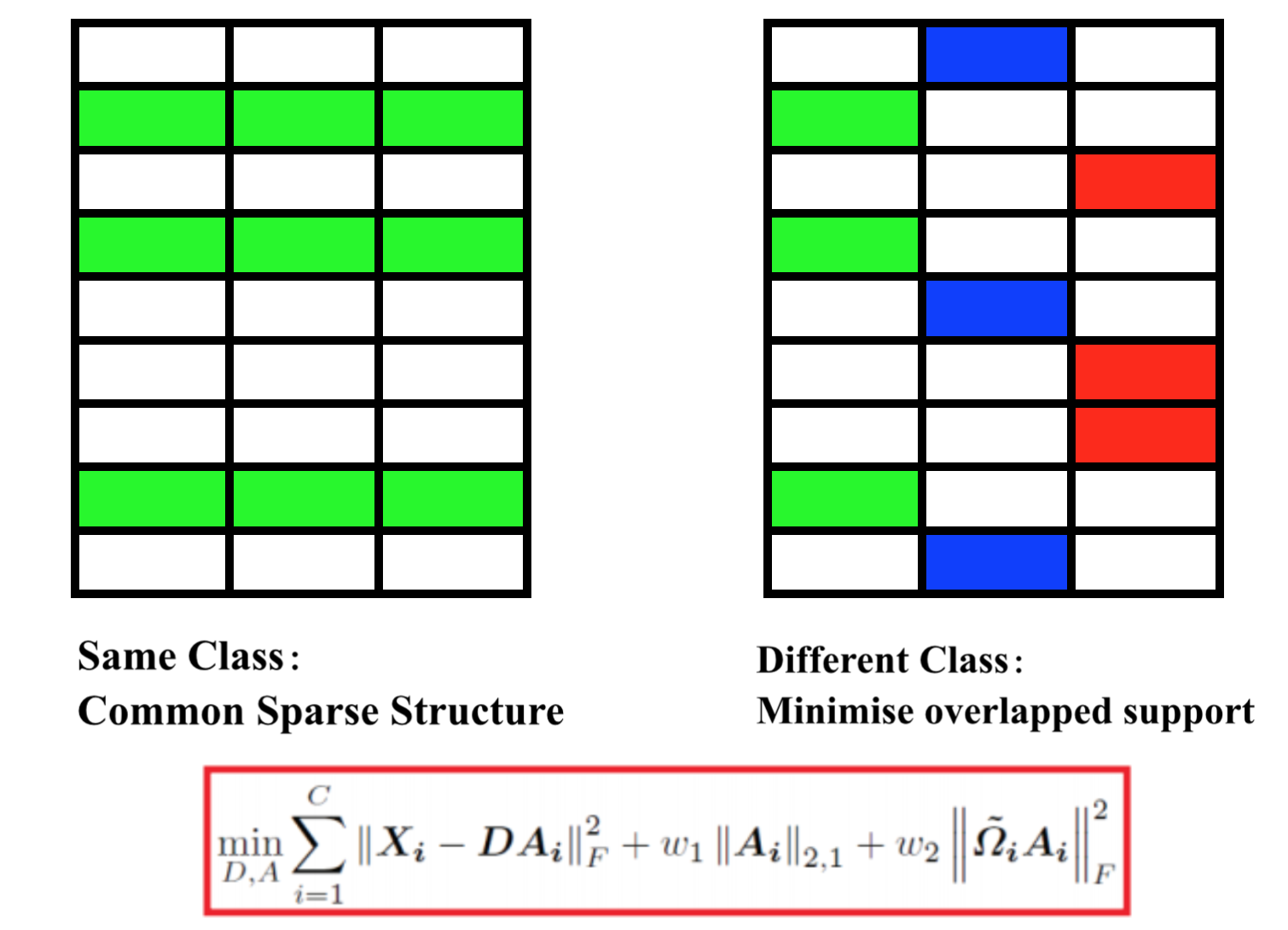
Support Discrimination Dictionary Learning for Image Classification Yang Liu, Wei Chen, Qingchao Chen and Ian Wassell European Conference on Computer Vision (ECCV), 2016 [PDF] [DOI] [Bibtex] |
|
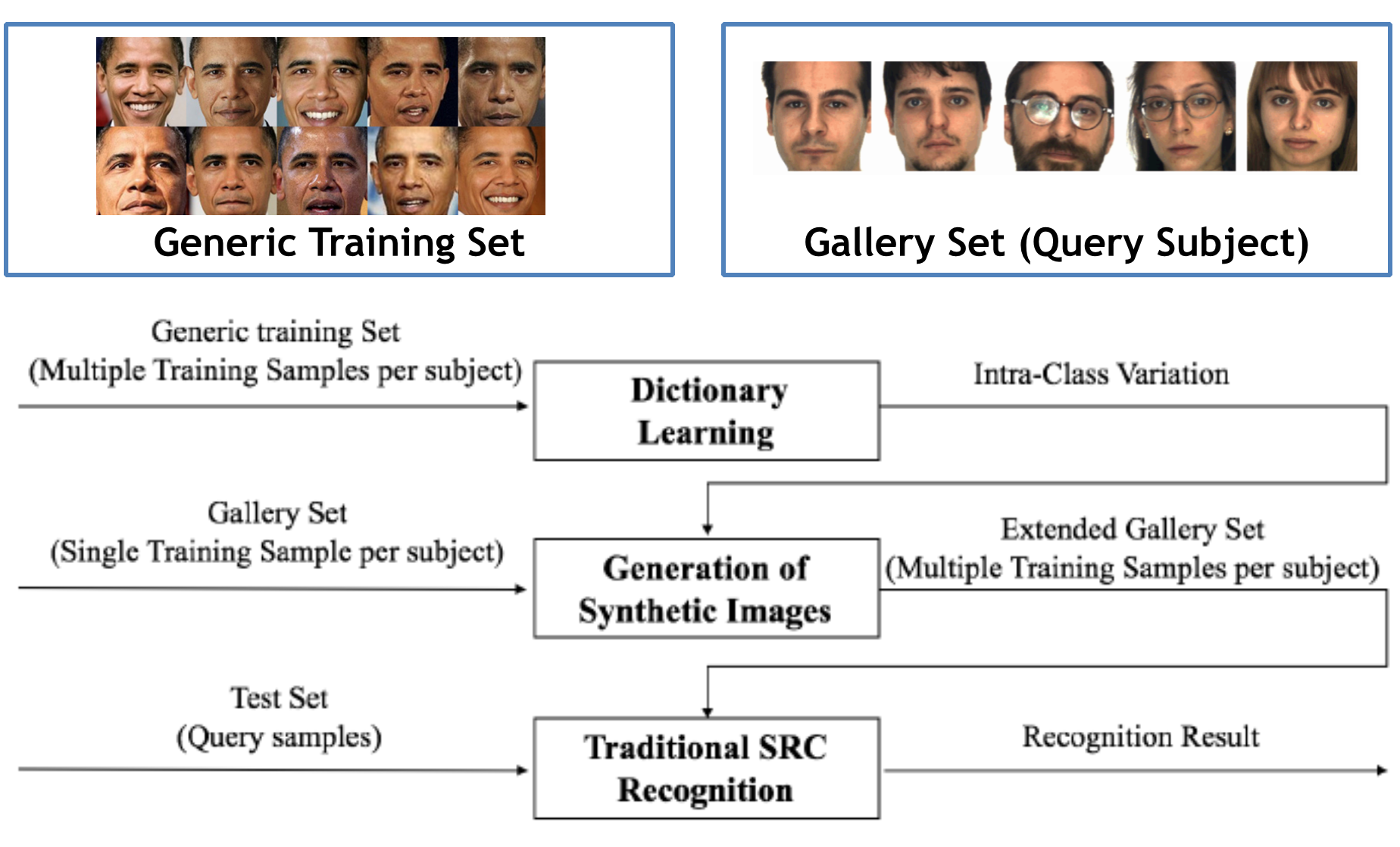
A New Face Recognition Algorithm based on Dictionary Learning for a Single Training Sample per Person Yang Liu and Ian Wassell British Machine Vision Conference (BMVC), 2015 [PDF] [DOI] [Bibtex] |
Work & Service

|
Mentor: Prof. Andrew Zisserman |

|
Mentors: Zhaowen Wang, Hailin Jin |
|
Mentor: Dr. Ian Wassell |

|
|

|
|
Awards
-
First Prize in CVPR International Ego4D Challenge (Social interaction) 2025
-
First Prize in CVPR International CulturalVQA Benchmark Challenge 2025
-
First Prize in CVPR International Embodied Scene Understanding Challenge 2023
-
First Prize in ECCV International Ego4D Challenge (Social interaction) 2022
-
Second Prize in International Makeup Temporal Video Grounding Challenge 2022
-
First Prize in International Condensed Movie Dataset Challenge 2021
-
Third Prize in International Multi-Moments in Time Challenge 2019
-
Second Prize in International Large Scale Movie Description Challenge 2019
-
Cambridge Trust Scholar 2014-2018
-
Thriplow Scholarship 2018
-
MariaMarina Scholarship 2017
-
Newton Trust Scholarship 2016
-
Honorary Studentship in Lucy Cavendish College in Cambridge 2014
-
Queen Mary College Prize 2013